Introduction¶
Definition of Extremes¶
There is no exact definition of an “extreme”. This is because it is an arbitrary classification of a real quantity.
Extreme Indices. These are based on the probability of relative occurrence. For example, we could say that the percentile of the observed maximum temperature. We typically assign a threshold which characterizes the severity of a probable outcome should the threshold be crossed. These are typically moderate extremes which are in the percentile.
Extreme Value Theory. These are based on a theory called the Extreme Value Theory (EVT). This is a more rigorous definition of extremes which involves more theory. We need EVT because of the sampling issues associated with these rare events; typically we only observe percentile of the total samples. In addition, EVT will allow us to estimate the probability of “values never seen”.
Example¶
For example, if we have a spatiotemporal field of precipitation, we could have different weather regimes. Simply precipitation makes up the bulk of observations, storms could make up the rare events, and hurricanes can make up the extreme events. One could fit a mean regressor on the thunderstorms (given precipitation) and treat the hurricanes as outliers. To estimate the 100-year storm, we would only focus on hurricanes.
Table 1:Extreme Events
| Classification | Percentile | Precipitation |
|---|---|---|
| Bulk | 0.95 | Precipitation |
| Rare Events | 0.05 | Storms |
| Extreme Events | 0.01 | Hurricanes |
Formulation¶
Three Interpretations
There are three interpretations of extreme value theory which are complementary. In a nutshell, there are three ways of selecting extreme values from data and then defining a likelihood function.
- Max Values —> GEVD
- Threshold + Max Values —> GPD
- Threshold + Max Values + Counts + Summary Statistic —> PP
Extreme value distributions (EVD) are the limiting distributions for the maximum/minimum of large collections of independent random variables from the same arbitrary distribution.
There are many instances of ways to measure extreme values. In particular, there are 3 ways of defining extremes: 1) maxima, 2) thresholding, 3) counting exceedences. The most common methods are the maxima
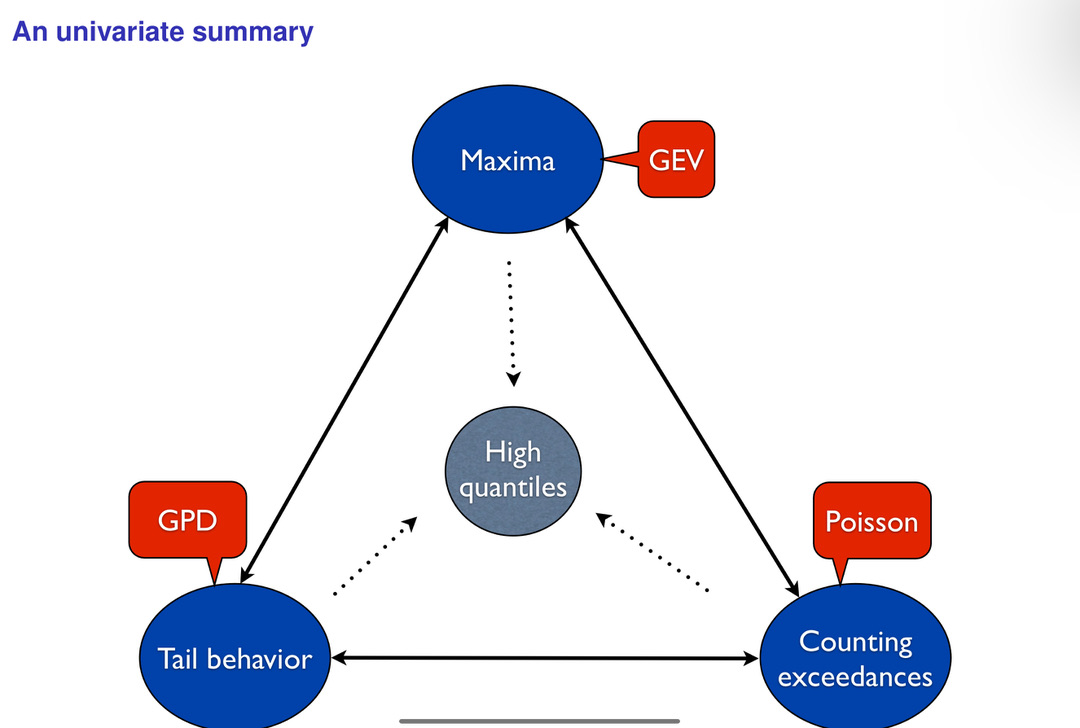
Figure 1:A figure from Philippe showcasing how we can model extreme values with three different perspectives: 1) maxima values and GEV, 2) tail behaviour with GPD, and 3) counting exceedences with Poisson processes. [Source]
Maxima¶
Here, we are looking at a maximum or minimum within a block of data (see example figure) A block is a set time period such as a week, a month, a season or a year. Note: we have to be careful about what we define as a valid time period because some scales exhibit high variability which could be miscategorized as an extreme. A typical application is to first find the annual maximum value of a spatiotemporal field. We could ask some questions like:
- In a given period/patch, how likelihood is an exceedance of a specific threshold?
- What threshold can be expected to be exceeded, on average, once every N period/patch?
An advantage of this method is that it is simple to apply and easy to interpret. However, some advantages of this method are that we remove a lot of information which results in framework is not as often directly useful and it is not the most efficient use of a spatiotemporal dataset.
Practical xample: Binning
A very simple example for maximum block estimation is to use a histogram which discretizes a continuous field. We would need to break a continuous field into sufficiently large enough discrete units and take the maximum of each block. A good package is the [`boost-histogram``]() package which works well with spatiotemporal data structures like `xarray`.
First, let’s get some pseudo data
y: Array["Ds Dt"] = ...Now, we need to describe the spatiotemporal discretization. This can be done via binning.
# create bins
latbins = np.arange(-90, 90, 100)
lonbins = np.arange(-180, 180, 100)
tbins = np.arange("1950", "2020", "Yearly")Now, we want to take the max value of each bin (TODO)
Generalized Extreme Value Distribution¶
In either case, the Fisher-Tippet Asymptotic Theorem (see wiki | youtube) dictates that extremes generated via a block maxima/minima method will converge to a generalized extreme value distribution (GEVD).
This basically says that your provided your underlying probability distribution function, , of a random variable, , is not highly unsual, regardless of what is, and provided that the t is sufficiently large, maxima samples of size drawn from will be distributed as the GEVD.
where , is the location parameter, is the scale parameter and is the shape parameter. The location parameter, μ, is not the mean of the distribution but rather the center of the distribution. Similarly, the scale parameter, σ, is not the standard deviation of the distribution but rather it governs the size of the deviations about μ. The shape parameter ξ describes the tail behaviour of the GEV distribution which is arguably the most important choice as it dictates the shape of the distribution (see figure). Below, we outline the cases:
Type I. The Gumbel distribution occurs when which results in light tails. It is used to model the maximum/minimum of a dataset as it extends over the entire range of real numbers. This is similar to other “light tailed” distributions like the Normal, LogNormal, Hyperbolic, Gamma, and Chi-Squared distributions. This is common when trying to describe the domain of attraction for common distributions like the normal, exponential or gamma. This is not typically found in real world data but there could be some transformed space whereby this is useful.
Type II. The Frechet distribution occurs when which results in heavy tails. This is similar to other “heavy tailed” distributions like the InverseGamma, LogGamma, T-student, and Pareto distributions. This is typically found for variables like precipitation / rainfall estimation, stream flow, flood analysis, human lifespan, financial returns and economic damage.
Case III. The Weibull distribution occurs when which results in bounded tails. This is similar to the Beta distribution This distribution is common for many variables like temperature, wind speed, pollutants, and sea level. It has also been known to
Once we have the parameters of this distribution, we can calculate the return levels. See my evaluation guide for more information on calculating return levels.
Choosing Distributions
On a practical note, we need to decide which case of the shape parameter we need to choose. We often choose this manually because there is research which shows that it is quite hard to fit via data. There are a few ways we can choose.
Strong Prior. The researcher will manually assign the case because they have strong prior knowledge, aka experience, and domain expertise.
Hypothesis Testing. One can conduct hypothesis testing by assigning a hypothesis and null hypothesis to each case.
Conservative. Fréchet is the most conservative estimate.
Tail Behaviour¶
Often times, we are not interested in the maximum values over a period/block. There are many instances where there is a specific threshold where all values above/below are of interest/concern. In this scenario, we may be interested in using the peaks-over-threshold (PIT) method. The POT approach is based on the idea of modelling data over a high enough threshold. We can select the threshold to trade-off the bias and variance.
On one hand, one could select a high threshold which will reduce the number of exceedances. This will increase the estimation variance and the reliability of the parameter estimates. However, this will result in a lower bias because we would get a better approximation of the GPD, i.e., less values --> higher variance, less bias. On the other hand, one could select a lower threshold which will induce a bias because the GPD could fit the exceedances poorly because we have more values, i.e., more values --> less variance, higher bias.
The advantage of this method is that it creates a relevant threshold of interest and it is an efficient use of data because we don’t remove information. The disadvantages of this method is that it is harder to implement and it is difficult to know when the conditions of the theory have been satisfied.
Note: a threshold can be selected by choosing a range of values and seeing which one of them provide a more stable estimation for other parameters. In other words, the estimates for the other parameters should be more or less similar.
Generalized Pareto Distribution¶
According to the Gnedenko-Pickands-Balkema-DeHaan (GPBdH) theorem (see wiki | youtube), using the POT method will converge to the generalized Pareto distribution (GPD) (Gilleland & Katz, 2016), i.e.
This basically says that your provided your underlying probability distribution function, , of a random variable, , is not highly unsual, regardless of what is, and provided that the threshold is sufficiently large, exceedances of will be distributed as the Generalized Pareto Distribution (GPD).
where is the high threshold st , is the scale parameter which depends on the threshold of , and is a the shape parameter. Similar to the GEVD, the shape parameter, ξ, determines the shape of the distribution and it is often very hard to fit. We outline some staple types of distributions defined by the shape parameter below.
Case I. The Pareto distribution occurs when which results in heavy tails. This is similar to “heavy-tailed” distributions like the Pareto-type distributions.
Case II. The expontial distribution occurs when which results in light tails. This is similar to other “light tail” distributions like the exponential-type distribution.
Case III. The Beta distribution occurs when which results in bounded tails. This is similar to other “bounded tailed” distributions like the Beta-type distributions.
Counting Exceedences (TODO)¶
We can use a counting process to model extremes: we count the excesses, i.e., the extreme values, , that fall above/below a threshold, ε.
Poisson Process (TODO)¶
This would be modelled as a sum of random binary events where the variable counds the number of variables about the threshold, which has a mean of . Poisson’s theorem shows us that if st
then follows approximately a Poisson variable . This is analogous to counting maximum/minimum values, i.e.,
where . Poisson’s work shows
Max-Stable Process¶
Let be a stochastic process with continuous sample paths. We assume that we have IID copies of available. We denote these samples by where and denotes the independent replications/realizations.
Let be the pointwise maximum of the underlying process . We can write this explicitly as
Our interest is only in the limiting process of for because it may provide an appropriate model in order to describe the behaviour of extremes. In particular, EVT says that if there exists a continuous function
and it has a non-degenerate marginal distribution , then this defines an extreme-value process.
Problems
- Spatiotemporal Dependencies - representation
- Measurements - very little, rare/extremely rare # of observations and complex
- Modeling - difficult with little measurements, even with simulations, things are complex and heavy, lose interpretability
- Experiment - what’s counterfactual?
- Causality - event attribution and direction
Resources¶
- Presentation by Reider (2014) - Slides (PDF)
- Extreme Value Theory: A Practical Introduction - Herman (200..) - Slides (PDF)
- Gilleland, E., & Katz, R. W. (2016). extRemes2.0: An Extreme Value Analysis Package inR. Journal of Statistical Software, 72(8). 10.18637/jss.v072.i08