Software¶
Software for Gaussian processes (GPs) have really been improving for quite a while now. It is now a lot easier to not only to actually use the GP models, but also to modify them improve them.
What is Deep Learning?¶
Before we get into the software, I just wanted to quickly define deep learning. A recent debate on twitter got me thinking about an appropriate definition and it helped me think about how this definition relates to the software. It gave me perspective.
Definition 1 by Yann LeCun - tweet (paraphrased)
Deep Learning is methodology: building a model by assembling parameterized modules into (possibly dynamic) graphs and optimizing it with gradient-based methods.
Definition II by Danilo Rezende - tweet (paraphrased)
Deep Learning is a collection of tools to build complex modular differentiable functions.
These definitions are more or less the same: deep learning is a tool to facilitate gradient-based optimization scheme for models. The data we use, the exact way we construct it, and how we train it aren't really in the definition. Most people might think a DL tool is the ensemble of different neural networks like these. But from henceforth, I refer to DL in the terms of facilitating the development of those neural networks, not the network library itself.
So in terms of DL software, we need only a few components:
- Tensor structures
- Automatic differentiation (AutoGrad)
- Model Framework (Layers, etc)
- Optimizers
- Loss Functions
Anything built on top of that can be special cases where we need special structures to create models for special cases. The simple example is a Multi-Layer Perceptron (MLP) model where we need some weight parameter, a bias parameter and an activation function. A library that allows you to train this model using an optimizer and a loss function, I would consider this autograd software (e.g. JAX). A library that has this functionality built-in (a.k.a. a layer), I would consider this deep learning software (e.g. TensorFlow, PyTorch). While the only difference is the level of encapsulation, the latter makes it much easier to build 'complex modular' neural networks whereas the former, not so much. You could still do it with the autograd library but you would have to design your entire model structure from scratch as well. So, there are still a LOT of things we can do with parameters and autograd alone but I wouldn't classify it as DL software. This isn't super important in the grand scheme of things but I think it's important to think about when creating a programming language and/or package and thinking about the target user.
Anatomy of good DL software¶
Francios Chollet (the creator of keras) has been very vocal about the benefits of how TensorFlow caters to a broad audience ranging from applied users and algorithm developers. Both sides of the audience have different needs so building software for both audiences can very, very challenging. Below I have included a really interesting figure which highlights the axis of operations.

Photo Credit: Francois Chollet Tweet
As shown, there are two axis which define one way to split the DL software styles: the x-axis covers the model construction process and the y-axis covers the training process. I am sure that this is just one way to break apart DL software but I find it a good abstract way to look at it because I find that we can classify most use cases somewhere along this graph. I'll briefly outline a few below:
- Case 1: All I care about is using a prebuilt model on some new data that my company has given me. I would probably fall somewhere on the upper right corner of the graph with the
Sequentialmodel and the built-intrainingscheme. - Case II: I need a slightly more complex training scheme because I want to learn two models that share hidden nodes but they're not the same size. I also want to do some sort of cycle training, i.e. train one model first and then train the other. Then I would probably fall somewhere near the middle, and slightly to the right with the
Functionalmodel and a customtrainingscheme. - Case III: I am a DL researcher and I need to control every single aspect of my model. I belong to the left and on the bottom with the full
subclassmodel and completely customtrainingscheme.
So there are many more special cases but by now you can imagine that most general cases can be found on the graph. I would like to stress that designing software to do all of these cases is not easy as these cases require careful design individually. It needs to be flexible.
Maybe I'm old school, but I like the modular way of design. So in essence, I think we should design libraries that focus on one aspect, one audience and do it well. I also like a standard practice and integration so that everything can fit together in the end and we can transfer information or products from one part to another. This is similar to how the Japanese revolutionized building cars by having one machine do one thing at a time and it all fit together via a standard assembly line. So in the end, I want people to be able to mix and match as they see fit. To try to please everyone with "one DL library that rules them all" seems a bit silly in my opinion because you're spreading out your resources. But then again, I've never built software from scratch and I'm not a mega coorperation like Google or Facebook, so what do I know? I'm just one user...in a sea of many.
With great power, comes great responsibility - Uncle Ben
On a side note, when you build popular libraries, you shape how a massive amount of people think about the problem. Just like expressiveness is only as good as your vocabulary and limited by your language, the software you create actively morphs how your users think about framing and solving their problems. Just something to think about.
Convergence of the Libraries¶
Originally, there was a lot of differences between the deep learning libraries, e.g. static v.s. dynamic, Sequential v.s. Subclass. But now they are all starting to converge or at least have similar ways of constructing models and training. Below is a quick example of 4 deep learning libraries. If you know your python DL libraries trivia, try and guess which library do you think it is. Click on the details below to find out the answer.
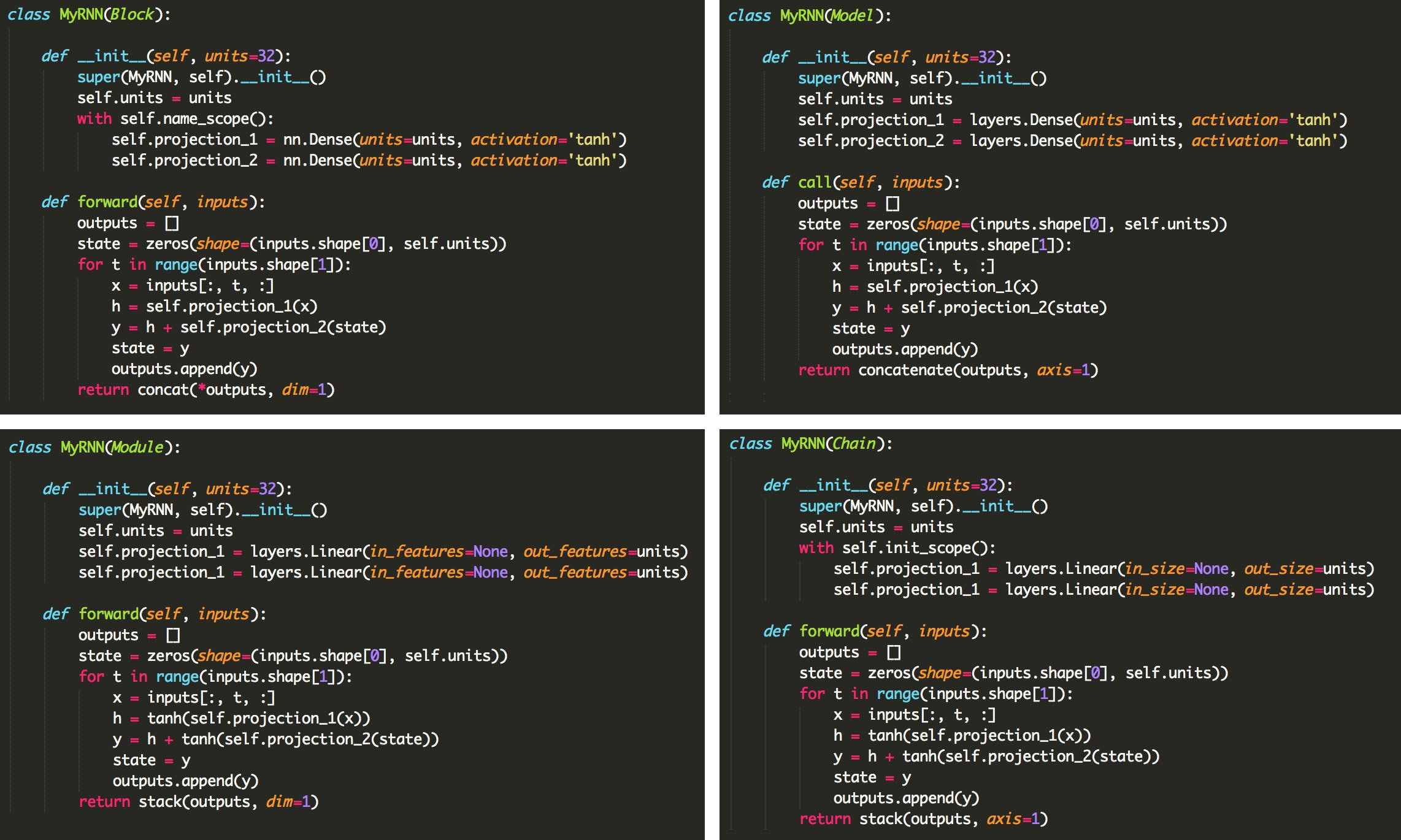
Photo Credit: Francois Chollet Tweet
Answer
| Gluon | TensorFlow |
| PyTorch | Chainer |
It does begs the question: if all of the libraries are basically the same, why are their multiple libraries? That's a great question and I do not know the answer to that. I think options are good as competition generally stimulates innovation. But at some point, there should be a limit no? But then again, the companies backing each of these languages are quite huge (Google, Microsoft, Uber, Facebook, etc). So I'm sure they have more than enough employees to justify the existence of their own library. But then again, imagine if they all put their efforts into making one great library. It could be an epic success! Or an epic disaster. I guess we will never know.
So how to classify a library's worth is impossible because it's completely subjective. But I like this chart by Francois Chollet who put the different depths a package can go to in order to create a package that caters to different users. But libraries typically can be classified on this spectrum. The same breakdown of Deep Learning algorithms into Models and Training can be done for GPs as well. Since GPs aren't super mainstream yet, most modern large scale GP libraries will fall in the fully flexible category. But recently, with the edition of TensorFlow probability and Edward2, we have more modern GPs that will fall into the Easy to use category (but not necessarily easy to train...).
Rant
One thing I don't like about the GP community is that it is quite split in terms of SOTA. This is reflected in the software. You'll have Andrew Gordon Wilson's spin-off that works a lot with Black-Box Matrix Multiplication (BBMMs) and then you'll have James Hensen's spin-off group that works a lot with methods of inducing points. The GPyTorch library scales amazingly but the GPFlow library has the best multi-output configuration I've ever seen. Either they don't know or they don't have time. But it would be nice if there was a one stop shop for all the algorithms so we can really get some cool benchmarks going when it comes to SOTA. Imagine something like this, this or this but with GPs from one library. I mean, I shouldn't complain, it's leagues better than it was. But we can do better...! :)
Python Packages¶
Below I list all of the GP packages available in Python. After this section, there will be more information on packages outside of the python ecosystem including some super intersting and well like GaussianProcess.jl for Julia and Stan as the universal programming language with many bindings.
Tip
If you're new to python, then I highly recommend you check out my other resource gatherings. It can be found here
TLDR - My Recommendations¶
Already Installed - scikit-learn
If you're already installed python through anaconda of some sort then
scikit-learnwill be there close to being default. It should be in everyone's toolbox so it's really easy to whip out a GP method with this library. If you don't have a lot of data points (10-1_000) then just use this. It will do the job.
Python Standard - PyMC3
This is the standard probabilistic programming language for doing Bayesian modeling in (more or less) standard Python. I personally think this library should also be in everyone's simple toolnox. The only thing that I don't like is that it uses Theano; it's not impossible but it's another API that you need to understand the moment you start trying to customize. However, the devs did a great job at making most of that API no necessary and it's very scalable on CPUs. So out of the box, you should be good!
From Scratch - JAX
If you like to do things from scratch in a very numpy-like way but also want all of the benefits of autograd on CPU/GPU/TPUs, then this is for you. If you want access to some distributions, you can always use numpyro or tensorflow-probability which both use JAX and have a JAX-backend respectively.
Standard / Researcher - GPFlow
I think the GPFlow library has the best balance of ease of use and customizability. It has a lot of nice little features that make it really nice to use out of the box while also allowing for customization. The only thing is that you're not going to get the most scalable nor does it inherit many SOTA methods in the GP community.
Researcher / Production - PyTorch
If you're doing GP research and you really know how to program, then I suggest you use GPyTorch. It is currently the most popular library for doing GP research and it hosts an entire suite of SOTA ready to go. In addition, it is the most scalable library to date. While the developers made it super easy to play with on the surface, you need to dig deep and put on your coder hat in order to get to things under the hood. So maybe contributing stuff might have a barrier.
Things Change
The machine learning community changes rapidly so any trends you observe are extremely volatile. Just like the machine learning literature, what's popular today can change within 6 months. So don't ever lock yourself in and stay flexible to cope with the changes. But also don't jump on bandwagons either as you'll be jumping every weekend. Keep a good balance and maintain your mental health.
scikit-learn¶





So we can start with the one that everyone has installed on their machine. The GP implementation in the scikit-learn library are already sufficient to get people started with GPs in scikit-learn. Often times when I'm data wrangling and I'm exploring possible algorithms, I'll already have the sklearn library installed in my conda environment so I typically start there myself especially for datasets with 100 points.
Sample Code
The sklearn implementation is as basic as it gets. If you are familiar with the scikit-learn API then you will have no problems using the GPR module. It's a three step process with very little things to change.
# initialize kernel function
kernel1 = RBF(length_scale=1.0) \
kernel2 = WhiteKernel(noise_level=0.1)
kernel = kernel1 + kernel2
# initialize noise parameter
alpha = 1e-5
# initialize optimizer
optimizer = "fmin_l_bfgs_b"
# initialize GP model
gpr_model = GaussianProcessRegressor(
kernel=kernel_gpml,
alpha=alpha,
optimizer=optimizer,
)
# train GP model
gpr_model.fit(Xtrain, ytrain)
# get predictions
y_pred, y_std = gpr_model.predict(Xtest, return_std=True)
Again, this is the simplest API you will find and for small data problems, you'll find that this works fine out-of-the-box. I highly recommend this when starting especially if you're not a GP connoisseur. What I showed above is as complicated as it gets. Any more customization outside of this is a bit difficult as the scikit-learn API for GPs isn't very modular and wasn't designed as such. But as a first pass, it's good enough.
Best Resource
- By far the best you'll see is the scikit-learn documentation.
- If you're feeling adventurous, you can check out how some people have extended this with additional kernels.
Verdict
✔️ Simple
✔️ Standard
❌ Simple. No SOTA. No Sparse models. No tricks.
❌ Hard to modify individual parts.
❌ No Autograd
GPy¶





GPy is the most comprehensive research library I have found to date. It has the most number of different special GP "corner case" algorithms of any package available. The GPy examples and tutorials are very comprehensive. The major caveat is that the documentation is very difficult to navigate. I also found the code base to be a bit difficult to really understand what's going on because there is no automatic differentiation to reduce the computations so there can be a bit of redundancy. I typically wrap some typical GP algorithms with some common parameters that I use within the sklearn .fit(), .predict(), .score() framework and call it a day. The standard algorithms will include the Exact GP, the Sparse GP, and Bayesian GPLVM.
Warning
This library does not get updated very often so you will likely run into very silly bugs if you don't use strict package versions that are recommended. There are rumors of a GPy2 library that's based on MXFusion but I have failed to see anything concrete yet.
??? note "Idea: Idea: Some of the main algorithms such as the sparse GP implementations are mature enough to be dumped into the sklearn library. For small-medium data problems, I think this would be extremely beneficial to the community. Some of the key papers like the (e.g. the FITC-SGP, VFE-SGP, Heteroscedastic GP, GP-LVM) certainly pass some of the strict sklearn criteria. But I suspect that it wouldn't be a joy to code because you would need to do some of the gradients from scratch. I do feel like it might make GPs a bit more popular if some of the mainstream methods were included in the scikit-learn library.
Sample Code
The GPy implementation is also very basic. If you are familiar with the scikit-learn API then you will have no problems using the GPR module. It's a three step process with very little things to change.
# define kernel function
kernel = GPy.kern.RBF(input_dim=1, variance=1., lengthscale=1.)
# initialize GP model
gpr_model = GPy.models.GPRegression(
Xtrain, ytrain,
kern=kernel
)
# train GP model
gpr_model.optimize(messages=True)
# get predictions
y_pred, y_std = gpr_model.predict(Xtest)
So as you can see, the API is very similar to the scikit-learn API with some small differences; the main one being that you have to initiate the GP model with the data. The rest is fairly similar. You should definitely take a look at the GPy docs if you are interested in some more advanced examples.
Best Resource
- By far the best you'll find are the GP Summer school labs that happen every year. (This year is virtual!)
- They have a lot of good examples on the website.
- The documentation is very extensive but very difficult to get to the nitty gritty details.
Verdict
✔️ Simple
✔️ Legacy
❌ Not industry battle-tested.
❌ No Autograd
GPyTorch¶





This is my defacto library for applying GPs to large scale data. Anything above 10,000 points, and I will resort to this library. It has GPU acceleration and a large suite of different GP algorithms depending upon your problem. I think this is currently the dominant GP library for actually using GPs and I highly recommend it for utility. They have many options available ranging from latent variables to multi-outputs. Recently they've just revamped their entire library and documentation with some I still find it a bit difficult to really customize anything under the hood. But if you can figure out how to mix and match each of the modular parts, then it should work for you.
Sample Code
In GPyTorch, the library follows the pythonic way of coding that became super popular from deep learning frameworks such as Chainer and subsequently PyTorch. It consists of a 4 step process which is seen in the snippet below.
Source - GPyTorch Docs
class MyGP(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood):
super().__init__(train_x, train_y, likelihood)
# Mean Function
self.mean_module = gpytorch.means.ZeroMean()
# Kernel Function
self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())
def forward(self, x):
mean = self.mean_module(x)
covar = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean, covar)
# train_x = ...; train_y = ...
likelihood = gpytorch.likelihoods.GaussianLikelihood()
model = MyGP(train_x, train_y, likelihood)
# Put model in train mode
model.train()
likelihood.train()
# Define optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
# Define loss function the marginal log likelihood
mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)
# training step
for i in range(training_iter):
# Zero gradients from previous iteration
optimizer.zero_grad()
# Output from model
output = model(train_x)
# Calc loss
loss = -mll(output, train_y)
# backprop gradients
loss.backward()
print('Iter %d/%d - Loss: %.3f lengthscale: %.3f noise: %.3f' % (
i + 1, training_iter, loss.item(),
model.covar_module.base_kernel.lengthscale.item(),
model.likelihood.noise.item()
))
optimizer.step()
# get the predictive mean class
f_preds = model(test_x)
# can do the same with we want the noise model
y_preds = likelihood(model(test_x))
# predictive mean
f_mean = f_preds.mean
# predictive variance
f_var = f_preds.variance
# predictive covariance
f_covar = f_preds.covariance_matrix
# sample from posterior distribution
f_samples = f_preds.sample(sample_shape=torch.Size(1000,))
I am only scratching the surface with this quick snippet. But I wanted to highlight how this fits into
Best Resource
- By far the best you'll see are form the GPyTorch documentation:
- The Tutorial
- The Examples. There are a lot.
-
Gaussian Processes (GP) with GPyTorch by DeepBayes.ru
A good tutorial from an outside perspective. Similar to the GPy tutorial.
Verdict
✔️ All working pieces to GP Model customizable
✔️ Lots of SOTA models
✔️ Super responsive devs
✔️ Integration with PyTorch and Pyro
❌ Difficult for absolute beginners
❌ Very difficult to contribute actual code
❌ Boilerplate Code
GPFlow¶





What Pyro is to PyTorch, GPFlow is to TensorFlow. This library is the successor to the GPy library. It is very comprehensive with a lot of SOTA algorithms. I definitely think ifA few of the devs from GPy went to GPFlow so it has a very similar style as GPy. But it is a lot cleaner due to the use of autograd which eliminates all of the code used to track the gradients. Many researchers use this library as a backend for their own research code so I would say it is the second most used library in the research domain. I didn't find it particularly easy to customize in tensorflow =<1.1 because of the session tracking which wasn't clear to me from the beginning. But now with the addition of tensorflow 2.0 and GPFlow adopting that new framework, I am eager to try it out again. They have a new public slack group so their network is going to grow hopefully.
Sample Code
Source: GPFlow Docs
# kernel function
kernel = gpflow.kernels.Matern52()
# mean function
meanf = gpflow.mean_functions.Linear()
# define GP model
gpr_model = gpflow.models.GPR(
data=(X, Y), kernel=kernel, mean_function=meanf
)
# define optimizer
optimizer = gpflow.optimizers.Scipy()
# optimize function
num_steps = 1_000
opt_logs = opt.minimize(
m.training_loss,
m.trainable_variables,
options=dict(maxiter=num_steps)
)
Best Resource
- By far the best you'll see are form the GPFlow documentation:
- Tutorials
- Integration with TensorFlow. There are a lot.
- Slack Channel
- StackOverFlow
Verdict
✔️ Customizable BUT GPy Familiar
✔️ Lots of SOTA models
✔️ Super responsive devs
✔️ Integration with TensorFlow and TensorFlow-probability
❌ Difficult for absolute beginners
❌ Very difficult to contribute actual code
❌ Missing some SOTA
Other Libraries¶
| Name | Language | Comments |
|---|---|---|
| PyMC3 | Python (Theano) | Probabilistic programming with exact and sparse implementations and HMC/NUTS inference. |
| Edward2 | Python (TensorFlow) | Implements drop-in GPs and Sparse GPs as keras layers. |
| MATLAB | MATLAB | They have their own native implementations (straight from Rasmussen) |
| gpml | MATLAB | Examples and code used in Rasmussen & Williams |
| GPstuff | MATLAB | A library with a wide range of inference methods. Including HMC. |
| GaussianProcess.jl | Julia | GP library utilising Julia's fast JIT compilation |
| Stan | R, Python, shell, MATLAB, Julia, Stata | Probabilistic programming using MCMC that can be easily be used to model GPs |
GPU Support¶
| Package | Backend | GPU Support |
|---|---|---|
| GPy | Numpy | ✓ |
| Scikit-Learn | Numpy | ✗ |
| PyMC3 | Theano | ✓ |
| TensorFlow (Probability) | TensorFlow | ✓ |
| Edward | TensorFlow | ✓ |
| GPFlow | TensorFlow | ✓ |
| Pyro.contrib | PyTorch | ✓ |
| GPyTorch | PyTorch | ✓ |
| PyMC4 | TensorFlow | ✓ |
Algorithms Implemented¶
| Package | GPy | Scikit-Learn | PyMC3 | TensorFlow (Probability) | GPFlow | Pyro | GPyTorch |
|---|---|---|---|---|---|---|---|
| Exact | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Moment Matching GP | ✓ | ✗ | ✓ | ✗ | S | S | ✓ |
| SparseGP - FITC | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| SparseGP - PEP | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| SparseSP - VFE | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| Variational GP | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ |
| Stochastic Variational GP | ✓ | ✗ | ✗ | S | ✓ | ✓ | ✓ |
| Deep GP | ✗ | ✗ | ✗ | S | S | ✓ | D |
| Deep Kernel Learning | ✗ | ✗ | ✗ | S | S | S | ✓ |
| GPLVM | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Bayesian GPLVM | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| SKI/KISS | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | |
| LOVE | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
Key
| Symbol | Status |
|---|---|
| ✓ | Implemented |
| ✗ | Not Implemented |
| D | Development |
| S | Supported |
| S(?) | Maybe Supported |