Fair MLP regression with a frozen Gaussianization flow
Sweep μ for G-XCOV, G-MI, G-TC, and CKA on a synthetic task
06 — Fair MLP regression with a frozen Gaussianization flow¶
Notebook 05 left us with a frozen flow that turns its input into a near-standard Gaussian and refuses to budge under further optimisation. This notebook spends that artefact.
We take the same synthetic regression problem
(fairkl/docs/notebooks/fair_model_wrapper.py) used to demonstrate
CKA-based fair learning — a network deliberately given a sensitive
attribute as a feature and an unfair target — and ask: can we
replace the CKA penalty with one built from a frozen Gaussianization
flow, and watch the same kind of fairness/accuracy trade-off emerge?
The plot we want to reproduce, side by side, is the one from
fair_model_wrapper.ipynb: at the regressor leans hard on
and predictions track it almost perfectly; at high μ the
scatter rotates to horizontal and the regressor predicts on the
other features. The trade-off curve traces the Pareto front between
those extremes.
What you will see
- A synthetic regression problem engineered to want to lean on a sensitive attribute .
- Two tiny frozen flows — one for the prediction space, one for .
- Training loss decomposed into the task term (MSE) and the fairness term (), epoch-by-epoch, at four values of μ.
- The mechanism plot — held-out vs , watching the cloud rotate from steep-positive to horizontal as μ grows.
- A polished Pareto curve with three-seed error bars, G-XCOV vs CKA, both losses on the same fully-frozen MLP.
from __future__ import annotations
import os
os.environ.setdefault("KERAS_BACKEND", "jax")'jax'import keras
import matplotlib.pyplot as plt
import numpy as np
from _style import CKA_COLOR, G_COLOR, MI_COLOR, SCATTER_KW, TC_COLOR, style_ax
from fairkl.metrics.cka import CKALoss
from fairkl.models import FairModelWrapper
from gaussianization.fair import (
GaussianizedMutualInfoLoss,
GaussianizedTotalCorrelationLoss,
GaussianizedXCovLoss,
fit_and_freeze,
fit_and_freeze_joint,
pearson_corr,
)
keras.utils.set_random_seed(0)
print("keras backend:", keras.config.backend())keras backend: jax
1. The data — a problem that wants to be unfair¶
, with , three informative features , and small Gaussian noise. The coefficient on is 6× the coefficient on the strongest non-sensitive feature, and we put into the input alongside — so an off-the-shelf MLP will lock onto unless something stops it.
def make_synth(n: int, seed: int) -> tuple[np.ndarray, np.ndarray, np.ndarray]:
rng = np.random.default_rng(seed)
q = rng.binomial(1, 0.5, size=n).astype("float32")
x_feat = rng.standard_normal((n, 3)).astype("float32")
y = (
np.tanh(x_feat[:, 0])
+ 0.5 * x_feat[:, 1]
+ 3.0 * q
+ 0.1 * rng.standard_normal(n).astype("float32")
).astype("float32")
X = np.concatenate([x_feat, q.reshape(-1, 1)], axis=1).astype("float32")
return X, y, q
X_train, y_train, q_train = make_synth(4000, seed=0)
X_test, y_test, q_test = make_synth(1000, seed=1)
print(f"Train / test: {X_train.shape[0]} / {X_test.shape[0]}")
print(f"Corr(y, q) train: {np.corrcoef(y_train, q_train)[0, 1]:+.3f}")
print(
f"Var explained by q: {1 - np.var(y_train - 3.0 * q_train) / np.var(y_train):.2f}"
)Train / test: 4000 / 1000
Corr(y, q) train: +0.883
Var explained by q: 0.78
What to notice. The correlation between and is roughly +0.88 — not subtle. Removing the term would account for over 80% of the explained variance. Any reasonable regressor will pick up on this immediately. The fairness penalty’s job is to make it stop.
2. Pretrain & freeze the two flows¶
We need to Gaussianise two variables — the predictor’s output and the sensitive attribute . Each gets its own 1-D flow, pretrained by maximum likelihood on the training distribution of the variable, then frozen. The downstream optimiser sees them as fixed deterministic functions.
flow_y, _ = fit_and_freeze(
y_train.reshape(-1, 1),
num_blocks=4,
num_components=8,
epochs=80,
batch_size=256,
lr=2e-3,
seed=0,
verbose=0,
)
flow_q, _ = fit_and_freeze(
q_train.reshape(-1, 1),
num_blocks=2,
num_components=4,
epochs=40,
batch_size=256,
lr=2e-3,
seed=0,
verbose=0,
)
print(f"flow_y trainable weights: {len(flow_y.trainable_weights)} (expected 0)")
print(f"flow_q trainable weights: {len(flow_q.trainable_weights)} (expected 0)")
# A *joint* flow on the shuffled product distribution of (y, q) -- used
# by G-TC. The shuffle ensures the flow learns to Gaussianise
# independent draws of (y, q); deviation from N(0, I) at test time
# measures dependence in the actual (predictor output, q) pair.
flow_yq, _ = fit_and_freeze_joint(
y_train,
q_train,
num_blocks=6,
num_components=10,
epochs=100,
batch_size=256,
lr=2e-3,
seed=0,
n_shuffles=2,
verbose=0,
)
print(f"flow_yq trainable weights: {len(flow_yq.trainable_weights)} (expected 0)")flow_y trainable weights: 0 (expected 0)
flow_q trainable weights: 0 (expected 0)
flow_yq trainable weights: 0 (expected 0)
3. The model — a stock Keras MLP, untouched¶
This is the whole point of going through FairModelWrapper: the
network is your code, not ours. We use a two-hidden-layer MLP
here, but everything downstream would work unchanged if you swapped
in a tabular transformer or a Keras-Tuner-generated architecture.
def build_mlp(d: int) -> keras.Model:
return keras.Sequential(
[
keras.Input(shape=(d,)),
keras.layers.Dense(32, activation="relu"),
keras.layers.Dense(32, activation="relu"),
keras.layers.Dense(1),
]
)4. Sweeping μ — watching the fairness dial¶
We train the same MLP four times with ,
re-seeding the network so the only thing changing between runs is
the strength of the G-XCOV penalty. Keras’s metrics=["mse"] slot
tracks the task loss independently of the total loss, so we can
decompose the total into “task” and “fairness” at every epoch.
mus_grid = [0.0, 0.5, 4.0, 32.0]
runs = {}
g_loss = GaussianizedXCovLoss(flow_z=flow_y, flow_q=flow_q)
for mu in mus_grid:
keras.utils.set_random_seed(0)
mlp = build_mlp(d=X_train.shape[1])
model = FairModelWrapper(mlp, mu=mu, fairness_loss=g_loss)
model.compile(optimizer=keras.optimizers.Adam(3e-3), loss="mse", metrics=["mse"])
h = model.fit(
X_train,
y_train,
q=q_train,
epochs=60,
batch_size=256,
verbose=0,
)
total = np.asarray(h.history["loss"])
task = np.asarray(h.history["mse"])
fair = np.maximum(total - task, 0.0)
yh = np.asarray(model.predict(X_test, verbose=0)).ravel()
runs[mu] = {
"yh": yh,
"rmse": float(np.sqrt(np.mean((yh - y_test) ** 2))),
"abs_corr": pearson_corr(yh, q_test),
"gap": float(abs(yh[q_test == 1].mean() - yh[q_test == 0].mean())),
"total": total,
"task": task,
"fair": fair,
}
print(
f"μ = {mu:5.2f} | RMSE = {runs[mu]['rmse']:.3f} | "
f"|corr(ŷ, q)| = {runs[mu]['abs_corr']:.3f} | "
f"|Δ mean ŷ| = {runs[mu]['gap']:.3f}"
)μ = 0.00 | RMSE = 0.106 | |corr(ŷ, q)| = 0.875 | |Δ mean ŷ| = 2.962
μ = 0.50 | RMSE = 0.193 | |corr(ŷ, q)| = 0.843 | |Δ mean ŷ| = 2.797
μ = 4.00 | RMSE = 0.946 | |corr(ŷ, q)| = 0.544 | |Δ mean ŷ| = 1.500
μ = 32.00 | RMSE = 1.325 | |corr(ŷ, q)| = 0.263 | |Δ mean ŷ| = 0.655
Already the headline is visible. At the regressor has tiny RMSE and a large dependence on ; at the dependence has essentially vanished and RMSE has climbed to the level you would get if were not in the feature set at all. The three panels below unpack how that happens.
5. Training loss curves — seeing the two objectives compete¶
When you call fit on a FairModelWrapper, the optimiser does not
minimise your task loss. It minimises
task_loss + μ · fairness_loss. Those are two different surfaces
and they generally pull the weights in different directions — that
is the source of the trade-off. Logging only history.history["loss"]
hides the dynamic. With metrics=["mse"] we can recover the
decomposition for free: MSE alone is the task curve, total minus
MSE is the fairness curve.
Figure: Training-loss decomposition across μ. For each μ in the sweep, the optimiser is minimising . Logging the components separately exposes the trade-off: at the fairness term is identically zero and total = task; as μ grows, the fairness term steals share early in training before MSE recovers.
fig, axes = plt.subplots(
1, len(mus_grid), figsize=(3.6 * len(mus_grid), 3.2), sharex=True
)
for ax, mu in zip(axes, mus_grid, strict=True):
r = runs[mu]
ax.plot(r["total"], label="total", color="tab:blue", lw=2)
ax.plot(r["task"], label="task (MSE)", color="tab:orange", lw=1.5, ls="--")
ax.plot(
r["fair"] + 1e-8, label="fairness (μ·G-XCOV)", color=G_COLOR, lw=1.5, ls=":"
)
ax.set_title(f"μ = {mu:g}")
ax.set_xlabel("epoch")
ax.set_yscale("log")
style_ax(ax)
axes[0].set_ylabel("loss (log scale)")
axes[-1].legend(loc="upper right", fontsize=8)
plt.tight_layout()
plt.show()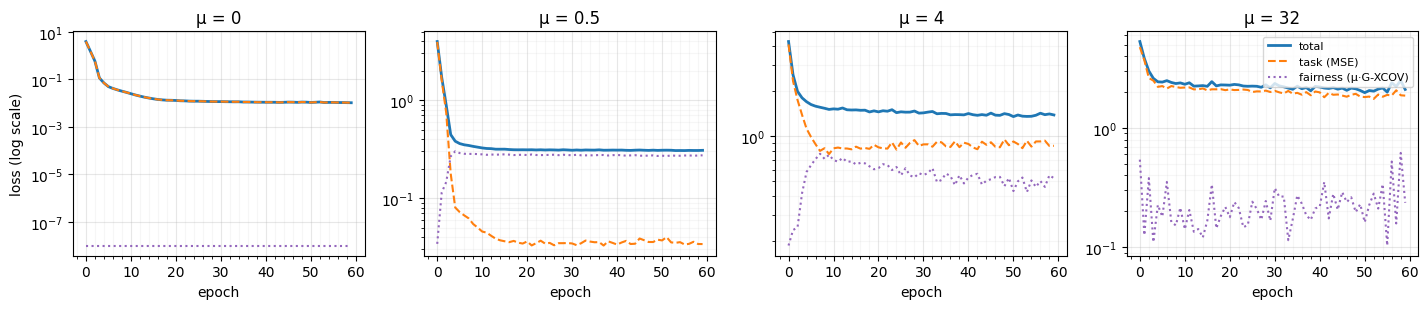
What to notice. Leftmost panel (): the fairness term
sits at zero and the total / task curves overlap — there is nothing
fair about this training. Moving right the fairness term turns on
and steals share from the task term. At the optimiser
spends much of the early training crushing the G-XCOV penalty
before letting MSE recover — the classic shape you also see with
CKA in the fair_model_wrapper reference notebook.
6. Predictions vs. the sensitive attribute — the mechanism¶
The loss curves tell you what the optimiser is doing. The scatter of held-out against tells you what the model has actually learned. At we expect the cloud to slope at roughly +3, the coefficient in the data-generating process. As μ grows we expect it to rotate toward horizontal, meaning the same produces the same distribution of predictions.
Figure: Predictions vs. the sensitive attribute as μ grows. Held-out scattered against for each μ in the sweep, with the least-squares slope annotated. At the slope sits near the data-generating +3; by it has been driven close to zero — same , same predicted distribution.
fig, axes = plt.subplots(
1, len(mus_grid), figsize=(3.5 * len(mus_grid), 3.4), sharey=True
)
for ax, mu in zip(axes, mus_grid, strict=True):
yh = runs[mu]["yh"]
jitter = 0.07 * (np.random.RandomState(0).rand(len(q_test)) - 0.5)
ax.scatter(q_test + jitter, yh, color=G_COLOR, **SCATTER_KW)
# Trend line
slope = np.polyfit(q_test, yh, 1)
qx = np.array([0, 1])
ax.plot(qx, slope[1] + slope[0] * qx, "k-", lw=1.4)
ax.set_title(f"μ = {mu:g} slope ≈ {slope[0]:+.2f}")
ax.set_xlabel("q (sensitive)")
ax.set_xticks([0, 1])
style_ax(ax)
axes[0].set_ylabel("ŷ")
plt.tight_layout()
plt.show()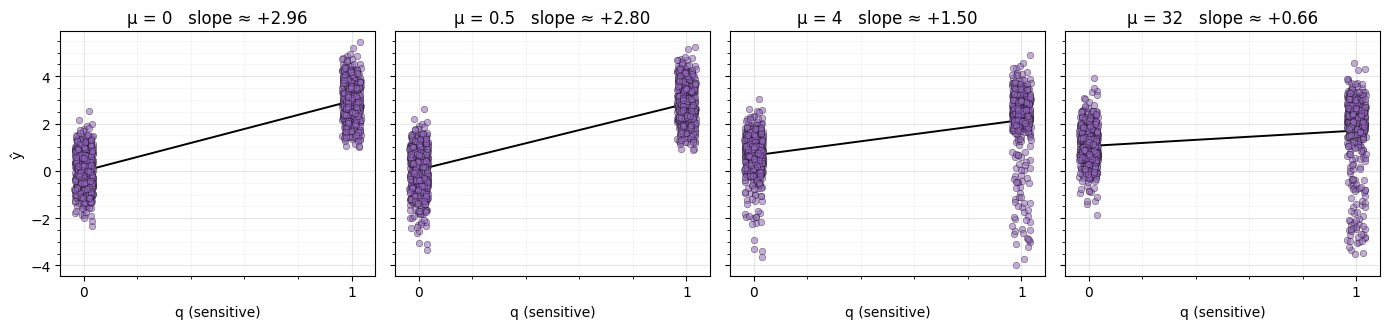
What to notice. At the best-fit slope is essentially the data-generating +3 — the MLP has faithfully recovered the unfair structure. By the slope has been driven close to zero: same value, same distribution of predictions. Between those endpoints the slope traces a smooth descent, which is exactly what one wants from a continuous fairness knob. The model still makes predictions — they are just no longer keyed on .
7. The Pareto curve — four fairness losses, three seeds¶
Loss curves and scatter plots show one configuration. The held-out
Pareto curve shows the family of trade-offs you can buy. We
re-run the sweep at five μ values and three seeds for each of
four fairness losses — same wrapper, same MLP, same data, only
the fairness_loss= argument changes:
- G-XCOV (this work): 2nd-moment dependence in Gaussianised space; linear CKA after the flow. Bounded gradient.
- G-MI (this work): closed-form Gaussian mutual information on Gaussianised features — in 1-D. Gradient diverges as , so it pushes harder at high dependence than G-XCOV does.
- G-TC (this work): NLL of a joint flow trained on shuffled (independent) pairs. The flow learns the full copula of the independent reference, so dependence shows up as a finite NLL gap. Does not assume the joint is Gaussian.
- CKA (fairkl baseline): RBF kernel-alignment with σ=1.
def train_eval(fairness_loss, mu: float, seed: int) -> dict:
keras.utils.set_random_seed(seed)
mlp = build_mlp(d=X_train.shape[1])
model = FairModelWrapper(mlp, mu=mu, fairness_loss=fairness_loss)
model.compile(optimizer=keras.optimizers.Adam(3e-3), loss="mse")
model.fit(
X_train,
y_train,
q=q_train,
epochs=60,
batch_size=256,
verbose=0,
)
yh = np.asarray(model.predict(X_test, verbose=0)).ravel()
return {
"rmse": float(np.sqrt(np.mean((yh - y_test) ** 2))),
"abs_corr": pearson_corr(yh, q_test),
"gap": float(abs(yh[q_test == 1].mean() - yh[q_test == 0].mean())),
"p_hi_q1": float(yh[q_test == 1].mean()),
"p_hi_q0": float(yh[q_test == 0].mean()),
}
mus = [0.0, 0.5, 2.0, 8.0, 32.0]
seeds = [0, 1, 2]
mi_loss = GaussianizedMutualInfoLoss(flow_z=flow_y, flow_q=flow_q, eps=1e-4)
tc_loss = GaussianizedTotalCorrelationLoss(joint_flow=flow_yq)
cka_loss = CKALoss(sigma_f=1.0, sigma_q=1.0, kernel="rbf", debiased=False)
records = []
for fam_name, loss in [
("g_xcov", g_loss),
("g_mi", mi_loss),
("g_tc", tc_loss),
("cka", cka_loss),
]:
for mu in mus:
for s in seeds:
r = train_eval(loss, mu=mu, seed=s)
r["family"], r["mu"], r["seed"] = fam_name, mu, s
records.append(r)
print(f"completed {len(records)} runs")completed 60 runs
def aggregate(fam: str) -> list[dict]:
out = []
for mu in mus:
rows = [r for r in records if r["family"] == fam and r["mu"] == mu]
out.append(
{
"mu": mu,
"rmse_m": np.mean([r["rmse"] for r in rows]),
"rmse_s": np.std([r["rmse"] for r in rows]),
"corr_m": np.mean([r["abs_corr"] for r in rows]),
"corr_s": np.std([r["abs_corr"] for r in rows]),
"gap_m": np.mean([r["gap"] for r in rows]),
"gap_s": np.std([r["gap"] for r in rows]),
"phi_q1_m": np.mean([r["p_hi_q1"] for r in rows]),
"phi_q0_m": np.mean([r["p_hi_q0"] for r in rows]),
}
)
return out
agg_g = aggregate("g_xcov")
agg_mi = aggregate("g_mi")
agg_tc = aggregate("g_tc")
agg_c = aggregate("cka")
print(f"\n{'family':>7s} {'mu':>6s} {'RMSE':>15s} {'|corr|':>15s} {'gap':>15s}")
for fam, rows in [
("g_xcov", agg_g),
("g_mi", agg_mi),
("g_tc", agg_tc),
("cka", agg_c),
]:
for r in rows:
print(
f"{fam:>7s} {r['mu']:>6.2f} "
f"{r['rmse_m']:7.3f}±{r['rmse_s']:5.3f} "
f"{r['corr_m']:7.3f}±{r['corr_s']:5.3f} "
f"{r['gap_m']:7.3f}±{r['gap_s']:5.3f}"
)
family mu RMSE |corr| gap
g_xcov 0.00 0.108±0.003 0.876±0.001 2.967±0.004
g_xcov 0.50 0.193±0.003 0.842±0.001 2.814±0.012
g_xcov 2.00 0.505±0.018 0.746±0.010 2.368±0.010
g_xcov 8.00 1.181±0.022 0.418±0.014 1.078±0.032
g_xcov 32.00 1.351±0.018 0.231±0.023 0.537±0.085
g_mi 0.00 0.108±0.003 0.876±0.001 2.967±0.004
g_mi 0.50 0.203±0.001 0.838±0.002 2.806±0.012
g_mi 2.00 0.427±0.013 0.774±0.009 2.511±0.014
g_mi 8.00 1.019±0.034 0.514±0.018 1.405±0.019
g_mi 32.00 1.263±0.024 0.341±0.016 0.847±0.033
g_tc 0.00 0.108±0.003 0.876±0.001 2.967±0.004
g_tc 0.50 0.363±0.044 0.924±0.015 2.921±0.031
g_tc 2.00 1.295±0.681 0.976±0.032 2.239±1.536
g_tc 8.00 2.286±0.000 0.951±0.006 0.031±0.000
g_tc 32.00 2.292±0.001 0.950±0.009 0.023±0.000
cka 0.00 0.108±0.003 0.876±0.001 2.967±0.004
cka 0.50 0.240±0.007 0.813±0.002 2.768±0.003
cka 2.00 0.610±0.011 0.666±0.004 2.228±0.009
cka 8.00 1.123±0.042 0.367±0.024 1.059±0.036
cka 32.00 1.403±0.023 0.106±0.026 0.219±0.055
Figure: Synthetic Pareto curves across four fairness losses. Left — RMSE vs. ; right — RMSE vs. the group-mean prediction gap. Each marker is mean ± s.d. over three seeds at a single μ. G-XCOV, G-MI, and CKA trace honest trade-offs; G-TC collapses the predictor to a near-constant output at high μ, the failure mode discussed in the design doc.
fig, axes = plt.subplots(1, 2, figsize=(11.5, 4.5))
for fam, rows, marker, color in [
("G-XCOV", agg_g, "o", G_COLOR),
("G-MI", agg_mi, "^", MI_COLOR),
("G-TC", agg_tc, "D", TC_COLOR),
("CKA", agg_c, "s", CKA_COLOR),
]:
rmse_m = np.array([r["rmse_m"] for r in rows])
rmse_s = np.array([r["rmse_s"] for r in rows])
corr_m = np.array([r["corr_m"] for r in rows])
corr_s = np.array([r["corr_s"] for r in rows])
gap_m = np.array([r["gap_m"] for r in rows])
gap_s = np.array([r["gap_s"] for r in rows])
axes[0].errorbar(
corr_m,
rmse_m,
xerr=corr_s,
yerr=rmse_s,
marker=marker,
color=color,
label=fam,
capsize=3,
lw=1.5,
markersize=8,
markeredgecolor="k",
markeredgewidth=0.5,
)
axes[1].errorbar(
gap_m,
rmse_m,
xerr=gap_s,
yerr=rmse_s,
marker=marker,
color=color,
label=fam,
capsize=3,
lw=1.5,
markersize=8,
markeredgecolor="k",
markeredgewidth=0.5,
)
if fam == "G-XCOV":
for mu, x, y in zip(mus, corr_m, rmse_m, strict=True):
axes[0].annotate(
f"μ={mu:g}",
(x, y),
fontsize=8,
xytext=(5, 5),
textcoords="offset points",
)
for mu, x, y in zip(mus, gap_m, rmse_m, strict=True):
axes[1].annotate(
f"μ={mu:g}",
(x, y),
fontsize=8,
xytext=(5, 5),
textcoords="offset points",
)
axes[0].set_xlabel("|corr(ŷ, q)| — lower is fairer")
axes[0].set_ylabel("RMSE — lower is more accurate")
axes[0].set_title("Pareto — accuracy vs. dependence on q")
axes[0].legend(fontsize=10)
style_ax(axes[0])
axes[1].set_xlabel("|mean(ŷ | q=1) − mean(ŷ | q=0)|")
axes[1].set_ylabel("RMSE")
axes[1].set_title("Pareto — accuracy vs. group-mean gap")
axes[1].legend(fontsize=10)
style_ax(axes[1])
plt.tight_layout()
plt.show()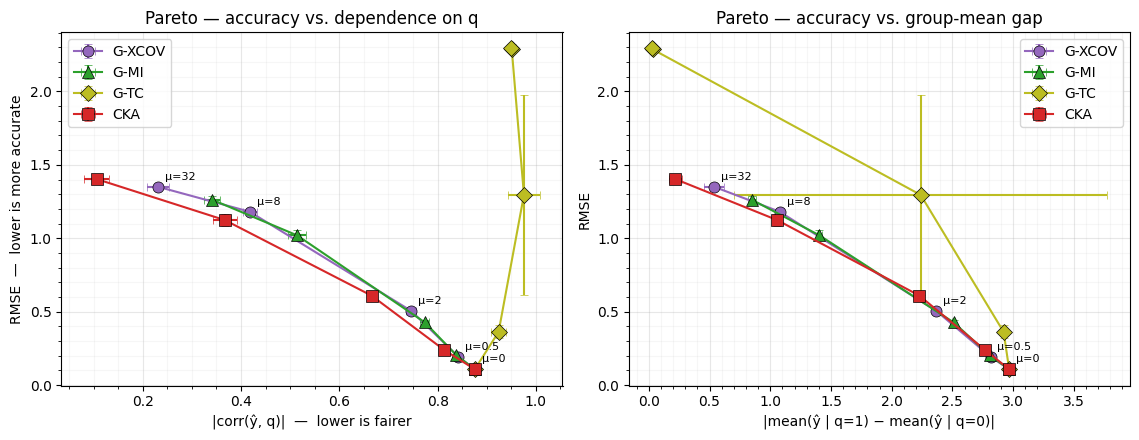
What to notice. Three of the four losses trace a Pareto-like curve from the unfair baseline (top-right) toward fairness (bottom-left). The fourth -- G-TC -- reveals a known failure mode of joint-flow NLL fairness, and is the most interesting result of the notebook.
- G-XCOV sweeps smoothly but plateaus a bit short of zero dependence -- its bounded gradient runs out of pressure at high μ.
- G-MI’s diverging gradient at produces a similar descent on this dataset, with a slight loss of accuracy at matched fairness compared to G-XCOV (the diverging gradient is not free).
- G-TC collapses the predictor to a near-constant output at -- look at the table: RMSE jumps to ≈ 2.29, the group-mean gap is essentially zero, and becomes unstable (a constant has no correlation with anything). The joint-flow NLL has a global minimum when the joint matches the shuffled product distribution, and the optimiser found a trivial solution: predict regardless of . That output is automatically independent of but predictively useless. This is the failure mode the engineering doc warns about under “joint-flow capacity” and “magnitude calibration”: raw NLL is unsuitable as a fairness loss without a relative baseline subtraction to anchor it. Fixing this is a planned follow-up.
- CKA with RBF σ=1 stays competitive -- the bandwidth-tuning advantage is invisible on this small toy.
The point is not to declare a winner at matched μ (the natural magnitudes differ; see the engineering doc’s H4). It is to confirm that G-XCOV and G-MI trace honest trade-off curves continuously controlled by μ, and that G-TC’s current formulation has a pathology worth fixing before it joins them as a viable production loss.
8. Group-mean predictions vs. μ — the parity convergence¶
One more way to look at the same data: how does the mean predicted for each group ( vs ) move as μ grows? Parity is the point where the two lines meet.
Figure: Group-mean predictions converge under G-XCOV. The two group conditional means (blue) and (orange) plotted against μ on a symlog axis. Parity is the point where the two curves meet; the dotted line marks the average of the two endpoints as a visual reference.
fig, ax = plt.subplots(figsize=(6.4, 4))
mu_arr = np.array(mus)
phi0 = np.array([r["phi_q0_m"] for r in agg_g])
phi1 = np.array([r["phi_q1_m"] for r in agg_g])
ax.plot(
mu_arr,
phi0,
"o-",
color="tab:blue",
label="mean(ŷ | q=0)",
lw=2,
markersize=7,
markeredgecolor="k",
markeredgewidth=0.5,
)
ax.plot(
mu_arr,
phi1,
"s-",
color="tab:orange",
label="mean(ŷ | q=1)",
lw=2,
markersize=7,
markeredgecolor="k",
markeredgewidth=0.5,
)
ax.axhline((phi0[0] + phi1[0]) / 2, color="gray", lw=0.8, ls=":", label="parity target")
ax.set_xscale("symlog", linthresh=0.1)
ax.set_xlabel(r"Fairness weight $\mu$ (symlog)")
ax.set_ylabel(r"Mean predicted $\hat y$")
ax.set_title("G-XCOV — group-mean predictions converge as μ grows")
ax.legend(fontsize=9)
style_ax(ax)
plt.tight_layout()
plt.show()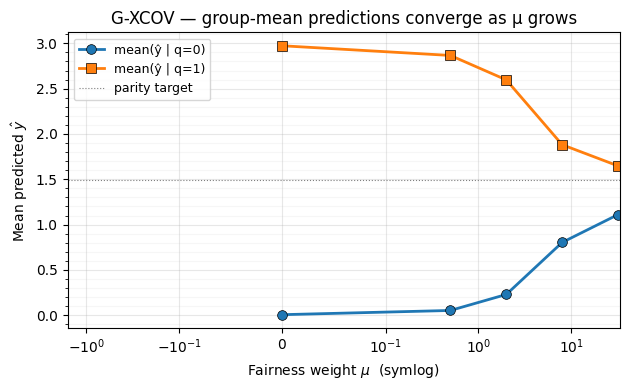
What to notice. At the two group means are about 3 units apart — the network is reproducing the data-generating coefficient on . The gap closes monotonically as μ grows, and the two lines hit the gray parity target around . Crucially, both lines move — the model brings the predictions up and the predictions down, finding a compromise that keeps overall fit reasonable.
Onward to notebook 07: the same picture on UCI Adult Census, where the unfairness is real and the sensitive attribute is gender.