Three ways to condition a flow
A conditional Gaussianizer maps each slice p(x|y) to the same N(0,I); the context y can enter at the base, the couplings, or both — and which you pick depends on whether y shifts the density or reshapes it
00 — Three ways to condition a flow¶
Parts 4-6 each learned a single density . Part 7 makes the flow’s parameters functions of a context , so one model represents a whole family — a conditional Gaussianizer that maps every conditional slice of the data to the same Winkler et al. (2019):
The NLL training, sampling, and log-det machinery are unchanged — only where enters. A flow has three slots for it:
- the base — a
ConditionalDiagGaussianwhose mean/scale are an MLP of (per-context location/scale); - the couplings —
RQSplineCoupling(cond_dim=...)concatenates onto the conditioner’s input (per-context shape); - a FiLM-style
Conditionerwrapper, for transforms that can’t natively read a context (rotations, normalisations) — previewed here, used in later parts.
Where the context can enter a flow (top) and how it enters one coupling (bottom):
The context can feed the couplings (reshaping each conditional slice) and/or the base (shifting/scaling it) — the four combinations we compare below.
A coupling already feeds the passive half into its conditioner; making it conditional just concatenates onto that input (the highlighted arrow). The triangular Jacobian — and hence the free log-det — is unchanged, so conditioning is nearly free.
We fit all four base×coupling combinations on class-conditional two moons — the label says which crescent a point belongs to — and let the per-class samples and the conditional NLL show which slot does what.
What you will see
- Four flows (none / base-only / coupling-only / both) under identical hyperparameters.
- Per-class samples — does each variant put mass on the right crescent?
- The conditional NLL ranking.
- The decision rule: base for shifts, couplings for shape.
import warnings
warnings.filterwarnings("ignore")
import equinox as eqx
import jax
import jax.numpy as jnp
import jax.random as jr
import matplotlib.pyplot as plt
import numpy as np
from flowjax.bijections import Permute
from flowjax.distributions import AbstractDistribution, Normal
from flowjax.train import fit_to_data
from sklearn.datasets import make_moons
from gauss_flows import ConditionalDiagGaussian, RQSplineCoupling, SurVAEFlow
from _style import DATA_COLOR, LATENT_COLOR, style_ax
jax.config.update("jax_enable_x64", True)1. Class-conditional two moons¶
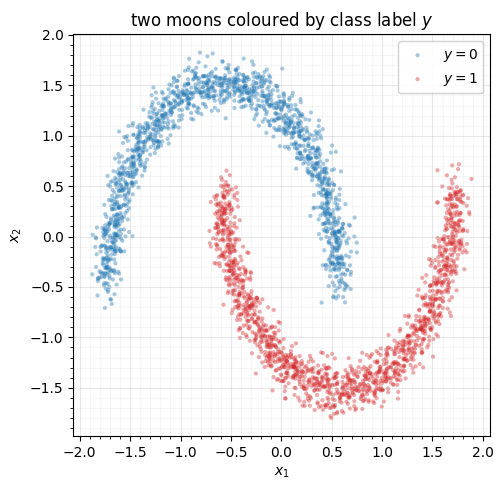
The same two-moons of Parts 4-5, but we keep the label make_moons returns:
is the upper crescent, the lower. So is a single crescent —
two well-separated conditional densities that differ in both position and shape,
which is exactly what lets the four variants separate. We one-hot the label as the
context .
N = 3000
X_raw, y = make_moons(n_samples=N, noise=0.06, random_state=0)
X = jnp.asarray((X_raw - X_raw.mean(0)) / X_raw.std(0))
C = jax.nn.one_hot(jnp.asarray(y), num_classes=2)
COND_DIM, EVENT = 2, (2,)
fig, ax = plt.subplots(figsize=(5.4, 5))
for cls, col in ((0, DATA_COLOR), (1, "tab:red")):
m = y == cls
ax.scatter(np.asarray(X[m, 0]), np.asarray(X[m, 1]), s=9, alpha=0.4,
color=col, edgecolors="none", label=f"$y={cls}$")
ax.set(title="two moons coloured by class label $y$", xlabel="$x_1$", ylabel="$x_2$")
ax.set_aspect("equal"); ax.legend(framealpha=0.9); style_ax(ax)
fig.tight_layout()
print(f"X {X.shape}, context C {C.shape}; per class: {int((y==0).sum())} / {int((y==1).sum())}")X (3000, 2), context C (3000, 2); per class: 1500 / 1500
2. Four configurations¶
Each flow is the same chain of four RQSplineCoupling layers (rational-quadratic
splines Durkan et al. (2019), 8 bins) with a fixed Permute between them so both
coordinates get transformed. The only difference is which slots read :
| flow | base | couplings | can model |
|---|---|---|---|
| none | unconditional | the marginal only — ignores | |
| base | unconditional | per-class shift | |
| coupling | cond_dim=2 | per-class shape | |
| both | cond_dim=2 | both |
N_LAYERS = 4
def make_flow(*, base_cond, coupling_cond, key):
bkey, *lkeys, pkey = jr.split(key, N_LAYERS + 2)
base = (ConditionalDiagGaussian(bkey, event_shape=EVENT, cond_shape=(COND_DIM,))
if base_cond else Normal(jnp.zeros(EVENT)))
cond_dim = COND_DIM if coupling_cond else None
perm = jr.permutation(pkey, jnp.arange(EVENT[0]))
transforms = []
for i, k in enumerate(lkeys):
transforms.append(RQSplineCoupling(k, shape=EVENT, n_bins=8, interval=4.0,
cond_dim=cond_dim, nn_width=64, nn_depth=2))
if i < N_LAYERS - 1:
transforms.append(Permute(perm))
return SurVAEFlow(base, transforms)
class Adapter(AbstractDistribution):
"""Wrap SurVAEFlow (log_prob signature x, key, condition) as a flowjax dist."""
flow: SurVAEFlow
shape: tuple
cond_shape: tuple | None
def __init__(self, flow):
self.flow, self.shape, self.cond_shape = flow, flow.data_shape, (COND_DIM,)
def _log_prob(self, x, condition=None):
return self.flow.log_prob(x, jr.key(0), condition=condition)
def _sample(self, key, condition=None):
return self.flow.sample(key, condition=condition)
CONFIGS = [("none", False, False), ("base", True, False),
("coupling", False, True), ("both", True, True)]
flows = {name: make_flow(base_cond=b, coupling_cond=c, key=jr.key(11 + i))
for i, (name, b, c) in enumerate(CONFIGS)}
for name, flow in flows.items():
n = sum(int(np.prod(p.shape)) for p in jax.tree_util.tree_leaves(eqx.filter(flow, eqx.is_array)))
print(f"{name:>9s} params: {n:6d}") none params: 24448
base params: 29056
coupling params: 24960
both params: 29568
3. Train all four — same objective, same hyperparameters¶
Every flow minimises the conditional NLL via
the same code path; only the layers’ cond_shapes differ. Two-moons is easy for
spline couplings, so a short run suffices.
def train(flow, key):
trained, losses = fit_to_data(key, Adapter(flow), (X, C), learning_rate=5e-3,
max_epochs=300, max_patience=40, batch_size=256,
val_prop=0.1, show_progress=False)
return trained.flow, losses
trained, losses_all = {}, {}
for i, (name, _, _) in enumerate(CONFIGS):
trained[name], losses_all[name] = train(flows[name], jr.key(20 + i))
print(f"{name:>9s} stopped at {len(losses_all[name]['train']):>3d} epochs, "
f"val NLL {float(min(losses_all[name]['val'])):+.4f}")
colors = {"none": "0.6", "base": DATA_COLOR, "coupling": "tab:green", "both": "tab:red"}
fig, ax = plt.subplots(figsize=(6.6, 4.2))
for name, _, _ in CONFIGS:
ax.plot(losses_all[name]["val"], color=colors[name], lw=2, label=name)
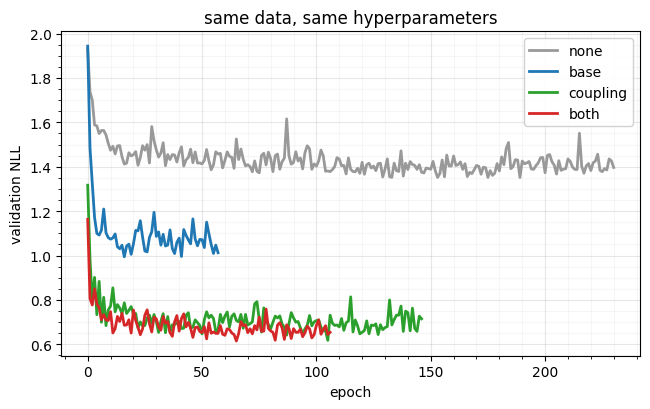
ax.set(xlabel="epoch", ylabel="validation NLL", title="same data, same hyperparameters")
ax.legend(framealpha=0.9); style_ax(ax)
fig.tight_layout() none stopped at 231 epochs, val NLL +1.3516
base stopped at 58 epochs, val NLL +0.9945
coupling stopped at 147 epochs, val NLL +0.6180
both stopped at 107 epochs, val NLL +0.6152
4. Per-class samples — does mass land on the right crescent?¶
Conditional sampling exploits invertibility: , then . For each class we overlay flow samples (one panel per config) on the true class data. The none flow has no label, so it samples the whole two-moons in both rows — half its mass lands in the wrong crescent.
classes = jnp.eye(2)
n_s = 1500
def flow_samples(flow, c, key):
cond = jnp.broadcast_to(c, (n_s, COND_DIM))
return jax.vmap(lambda k, ci: flow.sample(k, condition=ci))(jr.split(key, n_s), cond)
fig, axes = plt.subplots(2, 4, figsize=(15, 7.6), sharex=True, sharey=True)
for row, c in enumerate(classes):
cls = int(jnp.argmax(c))
true = X[y == cls]
for col, (name, _, _) in enumerate(CONFIGS):
ax = axes[row, col]
s = flow_samples(trained[name], c, jr.fold_in(jr.key(100 + col), row))
ax.scatter(np.asarray(true[:, 0]), np.asarray(true[:, 1]), s=7, alpha=0.35,
color=DATA_COLOR, edgecolors="none", label="true class")
ax.scatter(np.asarray(s[:, 0]), np.asarray(s[:, 1]), s=7, alpha=0.35,
color=colors[name], edgecolors="none", label="flow")
ax.set(xlim=(-2.2, 2.2), ylim=(-2.2, 2.2))
ax.set_aspect("equal"); style_ax(ax)
if row == 0:
ax.set_title(name)
if col == 0:
ax.set_ylabel(f"$y={cls}$")
if row == 0:
axes[0, 0].legend(loc="upper left", fontsize=8, framealpha=0.9)
fig.suptitle("Per-class samples: true class data (blue) vs flow samples (colour)", y=1.01)
fig.tight_layout()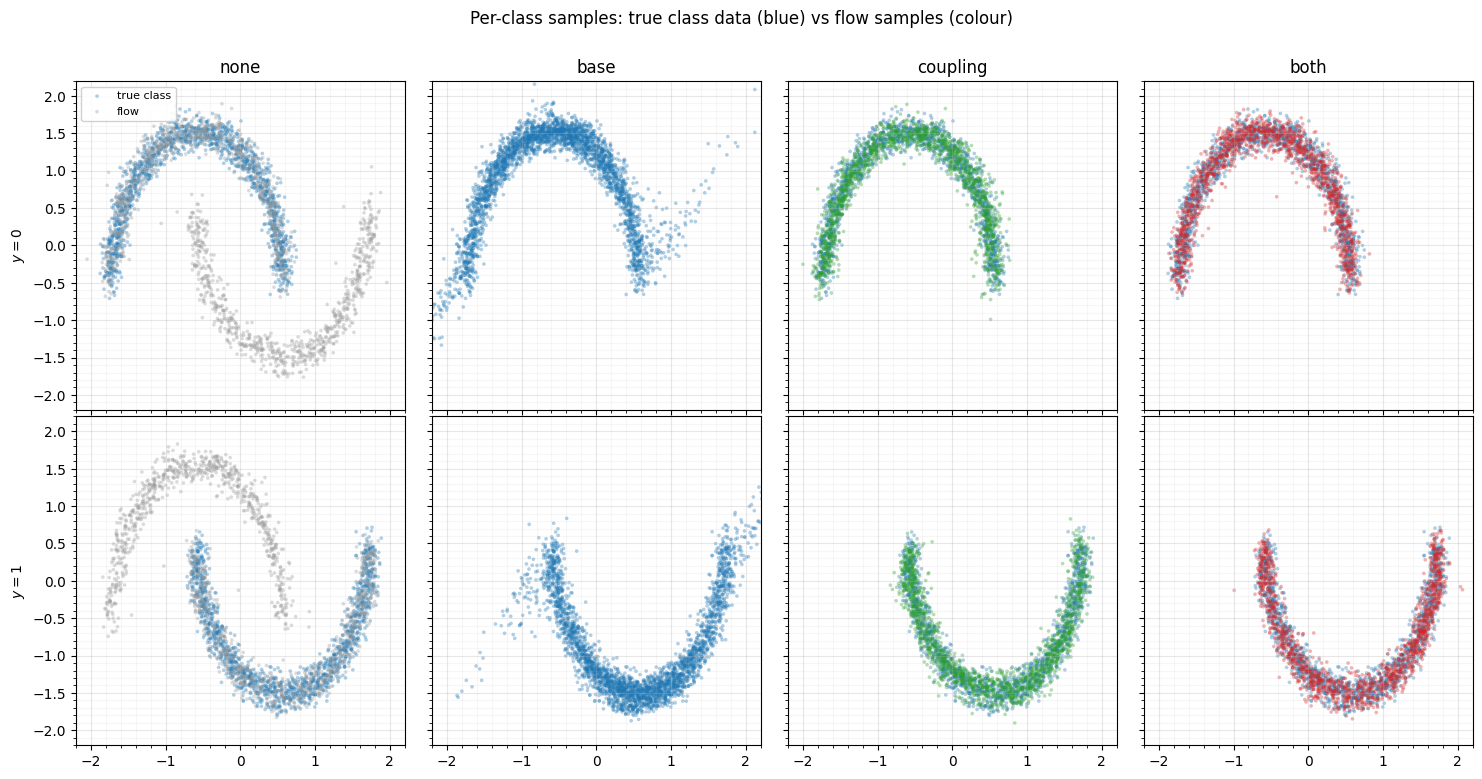
5. Conditional log-likelihood ranking¶
The mean conditional log-likelihood ranks the four — higher is better.
def mean_lp(flow):
f = eqx.filter_jit(lambda x, c: jax.vmap(lambda xi, ci: flow.log_prob(xi, jr.key(0), condition=ci))(x, c))
return float(jnp.mean(f(X, C)))
print("mean conditional log-likelihood (higher is better):")
for name, _, _ in CONFIGS:
print(f" {name:>9s}: {mean_lp(trained[name]):+.4f}")mean conditional log-likelihood (higher is better):
none: -1.3208
base: -0.9986
coupling: -0.6282
both: -0.6290
Recap — where to put the context¶
| if changes... | condition the... | why |
|---|---|---|
| only the location / scale of | base | one Gaussian per context, cheap |
| the shape of | couplings (cond_dim) | per-context map, -fold capacity |
| a transform that can’t read (rotation, norm) | wrap in Conditioner | FiLM modulation, keeps log-det closed-form |
The ranking tells the story: none ignores and pays for it; base-only fixes the per-class position but shares one crescent shape; coupling (and both) read the label inside the splines and produce genuinely class-specific crescents, so they win. Here the classes differ in shape, so the couplings carry the conditioning — but the principle is the headline of Part 7: decide, per slot, whether it should see , and the same threads through.
Next up. 01 — Conditional marginals & density estimation moves to a continuous context and a -dependent CDF, and checks that is calibrated — including the Gaussianization-direction view this notebook left implicit.
- Winkler, C., Worrall, D. E., Hoogeboom, E., & Welling, M. (2019). Learning Likelihoods with Conditional Normalizing Flows. arXiv Preprint arXiv:1912.00042.
- Durkan, C., Bekasov, A., Murray, I., & Papamakarios, G. (2019). Neural Spline Flows. Advances in Neural Information Processing Systems (NeurIPS).