Naive NerFs#
Neural Fields (NerFs) are an emerging class of coordinate-based neural networks. There has been many developments in the last few years for applying NerFs to data like images. In this tutorial, I will introduce NerFs from the geoscience perspective and highlight some potential advantages to using these methods. I will demonstrate some concrete work on sea surface height interpolation and highlight some of the problems (and potential solutions) I faced when applying this class of methods to spatiotemporal data.
import autoroot
import jax
import jax.numpy as jnp
import jax.scipy as jsp
import jax.random as jrandom
import optax
import numpy as np
import pandas as pd
import equinox as eqx
import xarray as xr
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm.notebook import tqdm, trange
from jaxtyping import Float, Array, PyTree, ArrayLike
import wandb
from dataclasses import dataclass
import hydra
from omegaconf import OmegaConf
sns.reset_defaults()
sns.set_context(context="talk", font_scale=0.7)
jax.config.update("jax_enable_x64", False)
%env XLA_PYTHON_CLIENT_PREALLOCATE=false
%matplotlib inline
%load_ext autoreload
%autoreload 2
Coordinate-Based Models#
Example I: Time Series
Example II: Images
Recap Formulation#
We are interested in learning non-linear functions \(\boldsymbol{f}\).
where the \(\boldsymbol{\phi}(\cdot)\) is a basis function. Neural Fields typically try to learn this basis funciton via a series of composite functions of the form
Problems#
Here, we will demonstrate a problem that a naive network has.
Data#
from dataclasses import dataclass
@dataclass
class FoxDM:
_target_: str = "jejeqx._src.datamodules.image.ImageFox"
batch_size: int = 10_000
resize: int = 2
shuffle: bool = False
split_method: str = "even"
image_url: str = "/gpfswork/rech/cli/uvo53rl/projects/jejeqx/data/images/fox.jpg"
config_dm = OmegaConf.structured(FoxDM())
dm = hydra.utils.instantiate(config_dm)
dm.setup()
init = dm.ds_train[:32]
x_init, y_init = init
img = dm.load_image()
img.shape
fig, ax = plt.subplots()
ax.imshow(img)
ax.set(xticks=[], yticks=[])
plt.tight_layout()
fig.savefig("./figures/demo/fox.png", dpi=100, transparent=True)
plt.show()

Coordinates#
print(f"Image Shape: {img.shape}")
print(f"Number of Coords: {len(dm.ds_train):,}")
Model#
The input data is a coordinate vector, \(\mathbf{x}_\phi\), of the image coordinates.
where \(D_\phi = [\text{x}, \text{y}]\). So we are interested in learning a function, \(\boldsymbol{f}\), such that we can input a coordinate vector and output a scaler/vector value of the pixel value.
MLP Layer#
where \(\sigma\) is the ReLU activation function.
from typing import Dict
from dataclasses import field
@dataclass
class Activation:
# _target_: str = "jejeqx._src.nets.activations.Tanh"
_target_: str = "jejeqx._src.nets.activations.ReLU"
@dataclass
class IdentityAct:
_target_: str = "equinox.nn.Identity"
@dataclass
class Key:
_target_: str = "jax.random.PRNGKey"
seed: int = 123
@dataclass
class MLPModel:
_target_: str = "equinox.nn.MLP"
in_size: int = 2
out_size: int = 3
width_size: int = 128
depth: int = 5
activation: Activation = Activation()
final_activation: IdentityAct = IdentityAct()
key: Key = Key(seed=42)
# initialize model
model_config = OmegaConf.structured(MLPModel())
model = hydra.utils.instantiate(model_config)
eqx.tree_pprint(model)
No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
MLP(
layers=(
Linear(
weight=f32[128,2],
bias=f32[128],
in_features=2,
out_features=128,
use_bias=True
),
Linear(
weight=f32[128,128],
bias=f32[128],
in_features=128,
out_features=128,
use_bias=True
),
Linear(
weight=f32[128,128],
bias=f32[128],
in_features=128,
out_features=128,
use_bias=True
),
Linear(
weight=f32[128,128],
bias=f32[128],
in_features=128,
out_features=128,
use_bias=True
),
Linear(
weight=f32[128,128],
bias=f32[128],
in_features=128,
out_features=128,
use_bias=True
),
Linear(
weight=f32[3,128],
bias=f32[3],
in_features=128,
out_features=3,
use_bias=True
)
),
activation=ReLU(),
final_activation=Identity(),
in_size=2,
out_size=3,
width_size=128,
depth=5
)
Note: We have created a function that takes a vector and outputs a vector. In JAX, we don’t have to think about batches until later.
# check output of models
x_vector, y_vector = x_init[0], y_init[0]
# predict
out_vector = model(x_vector)
assert out_vector.shape == y_vector.shape
Now, we can batches by autovectorizing using vmap.
# check output of models
out = jax.vmap(model)(x_init)
assert out.shape == y_init.shape
Optimizer (+ Learning Rate)#
For this, we will use a simple adam optimizer with a learning_rate of 1e-4. From many studies, it appears that a lower learning rate works well with this methods because there is a lot of data. In addition, a bigger batch_size is also desireable. We will set the num_epochs to 2_000 which should be good enough for a single image. Obviously more epochs and a better learning rate scheduler would result in better results but this will be sufficient for this demo.
import optax
num_epochs = 2_000
@dataclass
class Optimizer:
_target_: str = "optax.adam"
learning_rate: float = 1e-4
@dataclass
class Scheduler:
_target_: str = "optax.warmup_cosine_decay_schedule"
init_value: float = 0.0
peak_value: float = 1e0
warmup_steps: int = 500
end_value: float = 1e-5
use_scheduler = False
optim_config = OmegaConf.structured(Optimizer())
scheduler_config = OmegaConf.structured(Scheduler())
# initialize optimizer
optimizer = hydra.utils.instantiate(optim_config)
if use_scheduler:
num_steps_per_epoch = len(dm.ds_train)
scheduler = hydra.utils.instantiate(
scheduler_config, decay_steps=int(num_epochs * num_steps_per_epoch)
)
# initialize optimizer with scheduler
optimizer = optax.chain(optimizer, optax.scale_by_schedule(scheduler))
Scheduler#
We will use a simple learning rate scheduler - reduce_lr_on_plateau. This will automatically reduce the learning rate as the validation loss stagnates. It will ensure that we really squeeze out as much performance as possible from our models during the training procedure.We start with a (relatively) high learning_rate of 1e-4 so we will set the patience to 5 epochs. So if there is no change in with every epoch, we decrease the learning rate by a factor of 0.1.
This is a rather crude (but effective) method but it tends to work well in some situations. A better method might be the cosine_annealing method or the exponential_decay method. See other examples.
We are interested posterior of the parameters given the data. So we can use Bayes theorem to express this.
This can be solved by using the maximimum likelihood method. So in this case, we need to define the likelihood term for the data. We can assume a Gaussian likelihood because we are working with continuous data. To make things simple, we can also assume a constant noise.
This is the maximum likelihood estimation problem. If we assume our samples are i.i.d., we get the following minimization problem
Notice the slight of hand: the minimization of the negative log-likelihood is the same as the maxmimization of the log likelihood.
If we assume a noise level of 1, i.e. \(\sigma=1\), then this loss reduces to the mean squared error (MSE) loss function:
We can take minibatches
which is a proper subset of the dataset, \(\mathcal{B} \mathcal{D}=\mathcal{B}\).
So our new loss function will be:
Trainer Module#
import glob
import os
from pathlib import Path
from jejeqx._src.trainers.base import TrainerModule
from jejeqx._src.trainers.callbacks import wandb_model_artifact
from jejeqx._src.losses import psnr
class RegressorTrainer(TrainerModule):
def __init__(self, model, optimizer, **kwargs):
super().__init__(model=model, optimizer=optimizer, pl_logger=None, **kwargs)
def create_functions(self):
@eqx.filter_value_and_grad
def mse_loss(model, batch):
x, y = batch
pred = jax.vmap(model)(x)
loss = jnp.mean((y - pred) ** 2)
return loss
def train_step(state, batch):
loss, grads = mse_loss(state.params, batch)
state = state.update_state(state, grads)
psnr_loss = psnr(loss)
metrics = {"loss": loss, "psnr": psnr_loss}
return state, loss, metrics
def eval_step(model, batch):
loss, _ = mse_loss(model, batch)
psnr_loss = psnr(loss)
return {"loss": loss, "psnr": psnr_loss}
def test_step(model, batch):
x, y = batch
out = jax.vmap(model)(x)
loss, _ = mse_loss(model, batch)
psnr_loss = psnr(loss)
return out, {"loss": loss, "psnr": psnr_loss}
def predict_step(model, batch):
x, y = batch
out = jax.vmap(model)(x)
return out
return train_step, eval_step, test_step, predict_step
def on_training_end(
self,
):
if self.pl_logger:
save_dir = Path(self.log_dir).joinpath(self.save_name)
self.save_model(save_dir)
wandb_model_artifact(self)
self.pl_logger.finalize("success")
seed = 123
debug = False
enable_progress_bar = False
log_dir = "./"
trainer = RegressorTrainer(
model,
optimizer,
seed=seed,
debug=debug,
enable_progress_bar=enable_progress_bar,
log_dir=log_dir,
)
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.37384870648384094, 'psnr': 3.4702699184417725}
trainer.load_model("./checkpoints/checkpoint_model_mlp.ckpt")
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.008850343525409698, 'psnr': 41.5156135559082}
%%time
# metrics = trainer.train_model(dm, num_epochs=num_epochs)
CPU times: user 13 µs, sys: 3 µs, total: 16 µs
Wall time: 31.5 µs
# trainer.save_model("./checkpoints/checkpoint_model_mlp.ckpt")
# trainer.save_state("checkpoint_state.ckpt")
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.008850343525409698, 'psnr': 41.5156135559082}
all_metrics = pd.DataFrame(
data=[["mlp", metrics["loss"], metrics["psnr"]]],
columns=["model", "MSE", "SNR"],
)
all_metrics
| model | MSE | SNR | |
|---|---|---|---|
| 0 | mlp | 0.00885 | 41.515614 |
out_mlp = dm.coordinates_2_image(out)
fig, ax = plt.subplots(ncols=2, figsize=(8, 4))
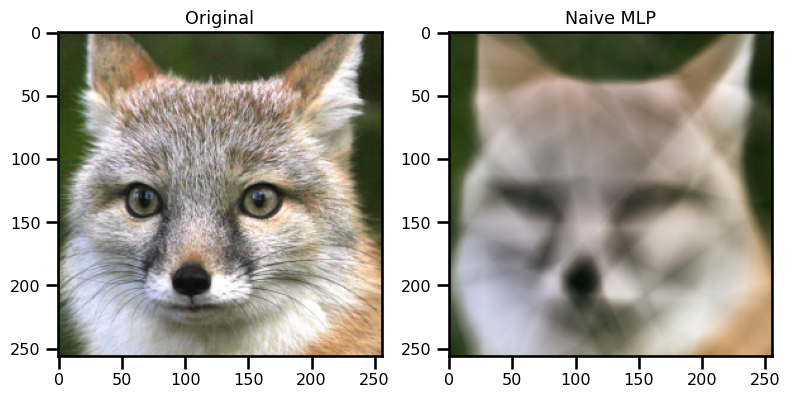
ax[0].imshow(img)
ax[0].set(title="Original")
ax[1].imshow(out_mlp)
ax[1].set(title="Naive MLP")
plt.tight_layout()
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
fig, ax = plt.subplots()
ax.imshow(out_mlp)
ax.set(xticks=[], yticks=[])
plt.tight_layout()
fig.savefig("./figures/demo/mlp.png", dpi=100, transparent=True)
plt.close()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Random Fourier Features#
where \(\boldsymbol{\Omega}\) is a random matrix sampled from a Gaussian distribution.
So our final neural network with the additional basis function:
where \(\boldsymbol{\phi}(\cdot)\) is the learned basis network.
from typing import Dict
from dataclasses import field
@dataclass
class RFFModel:
_target_: str = "jejeqx._src.nets.nerfs.ffn.RFFNet"
in_size: int = 2
out_size: int = 3
width_size: int = 256
depth: int = 5
ard: bool = True
method: str = "rbf"
key: Key = Key(seed=42)
# initialize model
model_config = OmegaConf.structured(RFFModel())
model = hydra.utils.instantiate(model_config)
# check output of models
out = jax.vmap(model)(x_init)
assert out.shape == y_init.shape
# eqx.tree_pprint(model)
seed = 123
debug = False
enable_progress_bar = False
log_dir = "./"
num_epochs = 6_000
trainer = RegressorTrainer(
model,
optimizer,
seed=seed,
debug=debug,
enable_progress_bar=enable_progress_bar,
log_dir=log_dir,
)
train_more = False
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.3707599341869354, 'psnr': 3.5415871143341064}
try:
trainer.load_model("./checkpoints/checkpoint_model_rff.ckpt")
except:
RuntimeError()
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.0028392504900693893, 'psnr': 53.401878356933594}
%%time
if train_more:
metrics = trainer.train_model(dm, num_epochs=num_epochs)
CPU times: user 16 µs, sys: 3 µs, total: 19 µs
Wall time: 36.2 µs
if train_more:
trainer.save_model("./checkpoints/checkpoint_model_rff.ckpt")
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.0028392504900693893, 'psnr': 53.401878356933594}
all_metrics = pd.concat(
[
all_metrics,
pd.DataFrame(
data=[["rff", metrics["loss"], metrics["psnr"]]],
columns=["model", "MSE", "SNR"],
),
]
)
all_metrics
| model | MSE | SNR | |
|---|---|---|---|
| 0 | mlp | 0.008850 | 41.515614 |
| 0 | rff | 0.002839 | 53.401878 |
out_rff = dm.coordinates_2_image(out)
fig, ax = plt.subplots(ncols=3, figsize=(12, 4))
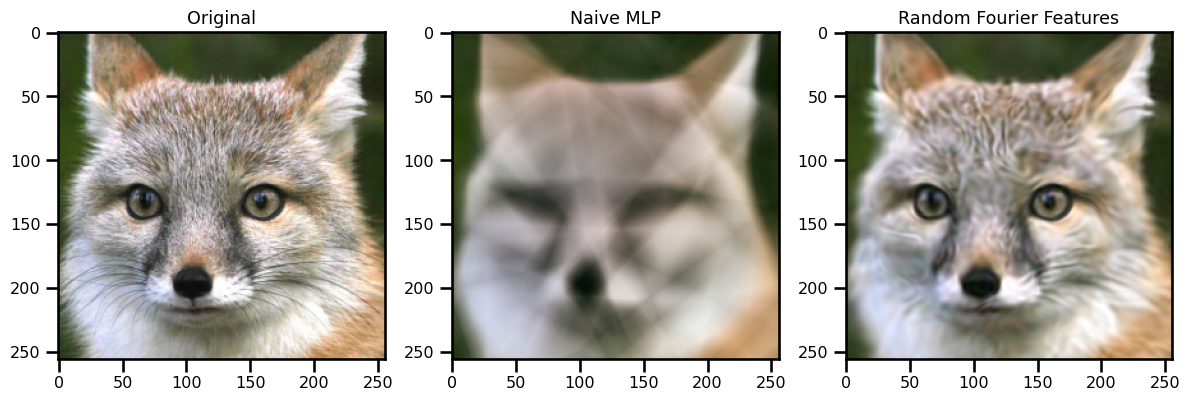
ax[0].imshow(img)
ax[0].set(title="Original")
ax[1].imshow(out_mlp)
ax[1].set(title="Naive MLP")
ax[2].imshow(out_rff)
ax[2].set(title="Random Fourier Features")
plt.tight_layout()
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
fig, ax = plt.subplots()
ax.imshow(out_rff)
ax.set(xticks=[], yticks=[])
plt.tight_layout()
fig.savefig("./figures/demo/ffn.png", dpi=100, transparent=True)
plt.close()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Custom Activation Functions#
SIREN
One of the most famous methods is the SIREN method. This replaces the standard activation function, \(\sigma\), with a sinusoidal function.
So our final neural network with the additional basis function:
where \(\boldsymbol{\phi}(\cdot)\) is the learned basis network.
@dataclass
class Key:
_target_: str = "jax.random.PRNGKey"
seed: int = 123
@dataclass
class SirenBasis:
_target_: str = "jejeqx._src.nets.nerfs.siren.SirenNet"
in_size: int = 2
out_size: int = 256
width_size: int = 256
depth: int = 5
key: Key = Key()
@dataclass
class LinearModel:
_target_: str = "equinox.nn.Linear"
in_features: int = 256
out_features: int = 3
use_bias: bool = True
key: Key = Key()
@dataclass
class NerFModel:
_target_: str = "jejeqx._src.nets.nerfs.base.NerF"
network: LinearModel = LinearModel()
basis_net: SirenBasis = SirenBasis()
from jejeqx._src.nets.nerfs.base import NerF
# initialize model
model_config = OmegaConf.structured(NerFModel())
model = hydra.utils.instantiate(model_config)
# check output of models
out = jax.vmap(model)(x_init)
# assert out.shape == y_init.shape
# eqx.tree_pprint(model)
out.shape
(32, 3)
seed = 123
debug = False
enable_progress_bar = False
log_dir = "./"
trainer = RegressorTrainer(
model,
optimizer,
seed=seed,
debug=debug,
enable_progress_bar=enable_progress_bar,
log_dir=log_dir,
)
train_more = False
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.47536465525627136, 'psnr': 0.8998086452484131}
try:
trainer.load_model("./checkpoints/checkpoint_model_siren.ckpt")
except:
pass
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.0019353348761796951, 'psnr': 57.65052795410156}
%%time
if train_more:
metrics = trainer.train_model(dm, num_epochs=num_epochs)
CPU times: user 15 µs, sys: 3 µs, total: 18 µs
Wall time: 34.1 µs
if train_more:
trainer.save_model("./checkpoints/checkpoint_model_siren.ckpt")
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
{'loss': 0.0019353348761796951, 'psnr': 57.65052795410156}
all_metrics = pd.concat(
[
all_metrics,
pd.DataFrame(
data=[["siren", metrics["loss"], metrics["psnr"]]],
columns=["model", "MSE", "SNR"],
),
]
)
out_siren = dm.coordinates_2_image(out)
fig, ax = plt.subplots(ncols=2, nrows=2, figsize=(8, 8))
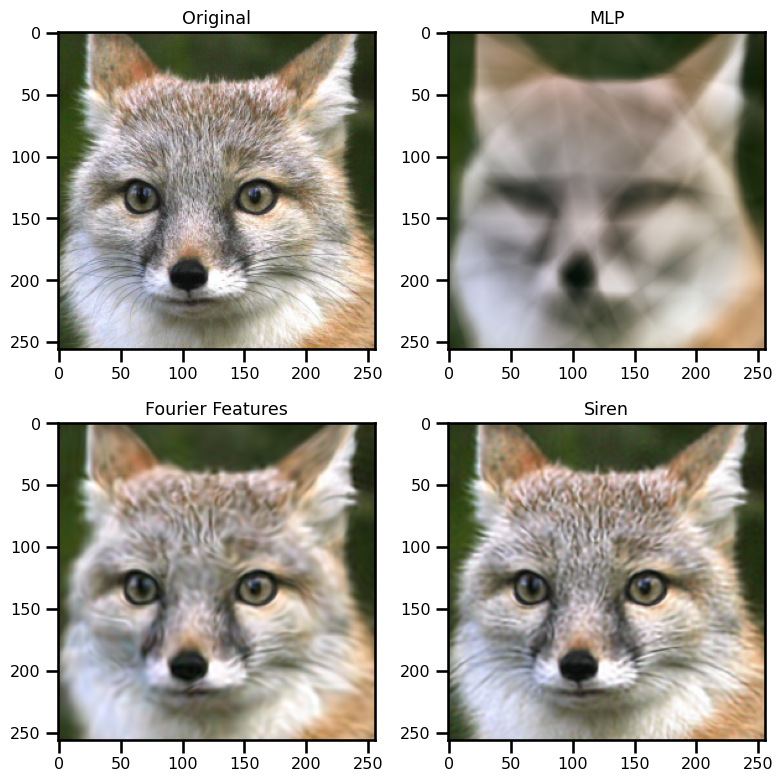
ax[0, 0].imshow(img)
ax[0, 0].set(title="Original")
ax[0, 1].imshow(out_mlp)
ax[0, 1].set(title="MLP")
ax[1, 0].imshow(out_rff)
ax[1, 0].set(title="Fourier Features")
ax[1, 1].imshow(out_siren)
ax[1, 1].set(title="Siren")
plt.tight_layout()
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
fig, ax = plt.subplots()
ax.imshow(out_siren)
ax.set(xticks=[], yticks=[])
plt.tight_layout()
fig.savefig("./figures/demo/siren.png", dpi=100, transparent=True)
plt.close()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
Multiplicative Filter Networks (MFN)#
Fourier Network#
import optax
num_epochs = 2_000
@dataclass
class Optimizer:
_target_: str = "optax.adam"
learning_rate: float = 1e-4
@dataclass
class Scheduler:
_target_: str = "optax.warmup_cosine_decay_schedule"
init_value: float = 0.0
peak_value: float = 1e0
warmup_steps: int = 500
end_value: float = 1e-5
use_scheduler = False
optim_config = OmegaConf.structured(Optimizer())
scheduler_config = OmegaConf.structured(Scheduler())
# initialize optimizer
optimizer = hydra.utils.instantiate(optim_config)
if use_scheduler:
num_steps_per_epoch = len(dm.ds_train)
scheduler = hydra.utils.instantiate(
scheduler_config, decay_steps=int(num_epochs * num_steps_per_epoch)
)
# initialize optimizer with scheduler
optimizer = optax.chain(optimizer, optax.scale_by_schedule(scheduler))
from typing import Dict
from dataclasses import field
@dataclass
class IdentityAct:
_target_: str = "equinox.nn.Identity"
@dataclass
class Key:
_target_: str = "jax.random.PRNGKey"
seed: int = 123
@dataclass
class MFNModel:
_target_: str = "jejeqx._src.nets.nerfs.mfn.FourierNet"
in_size: int = 2
out_size: int = 3
width_size: int = 256
depth: int = 4
final_activation: IdentityAct = IdentityAct()
key: Key = Key(seed=123)
# initialize model
model_config = OmegaConf.structured(MFNModel())
model = hydra.utils.instantiate(model_config)
# eqx.tree_pprint(model)
seed = 123
debug = False
enable_progress_bar = False
log_dir = "./"
trainer = RegressorTrainer(
model,
optimizer,
seed=seed,
debug=debug,
enable_progress_bar=enable_progress_bar,
log_dir=log_dir,
)
train_more = False
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
try:
trainer.load_model("./checkpoints/checkpoint_model_mfnfourier.ckpt")
except:
pass
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
%%time
if train_more:
metrics = trainer.train_model(dm, num_epochs=num_epochs)
if train_more:
trainer.save_model("./checkpoints/checkpoint_model_mfnfourier.ckpt")
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
all_metrics = pd.concat(
[
all_metrics,
pd.DataFrame(
data=[["mfnfourier", metrics["loss"], metrics["psnr"]]],
columns=["model", "MSE", "SNR"],
),
]
)
out_mfn_fourier = dm.coordinates_2_image(out)
fig, ax = plt.subplots(ncols=2, nrows=3, figsize=(8, 8))
ax[0, 0].imshow(img)
ax[0, 0].set(title="Original")
ax[0, 1].imshow(out_mlp)
ax[0, 1].set(title="MLP")
ax[1, 0].imshow(out_rff)
ax[1, 0].set(title="Fourier Features")
ax[1, 1].imshow(out_siren)
ax[1, 1].set(title="Siren")
ax[2, 1].imshow(out_mfn_fourier)
ax[2, 1].set(title="MFN (FourierNet)")
plt.tight_layout()
plt.show()
GaborNet#
from typing import Dict
from dataclasses import field
@dataclass
class IdentityAct:
_target_: str = "equinox.nn.Identity"
@dataclass
class Key:
_target_: str = "jax.random.PRNGKey"
seed: int = 123
@dataclass
class MFNModel:
_target_: str = "jejeqx._src.nets.nerfs.mfn.GaborNet"
in_size: int = 2
out_size: int = 3
width_size: int = 256
depth: int = 4
final_activation: IdentityAct = IdentityAct()
key: Key = Key(seed=123)
x_ = jrandom.normal(key=jrandom.PRNGKey(123), shape=(10,))
y_ = jrandom.normal(key=jrandom.PRNGKey(42), shape=(10, 20))
from scipy.spatial.distance import pdist, cdist
import einops
cdist(einops.repeat(x_, "D -> D R", R=20), y_, metric="sqeuclidean").shape
def norm(x, y):
a = np.sum(x**2, axis=-1)[..., None]
b = np.sum(y**2, axis=0)[None, :]
c = -2 * a @ b
D = a + b + c
return D.squeeze()
def norm2(x, y):
a = np.sum(x**2, axis=-1)[..., None]
b = np.sum(y**2, axis=0)[None, :]
c = np.einsum("i,ij->j", x, y)
D = a + b - 2 * c
return D.squeeze()
def norm3(x, y):
a_min_b = x[..., None] - y
D = np.einsum("ij,ij->j", a_min_b, a_min_b)
return np.sqrt(D).squeeze()
def norm4(x, y):
return np.linalg.norm(x[..., None] - y, ord=2, axis=1)
norm(x_, y_), norm2(x_, y_), norm3(x_, y_), norm4(x_, y_)
o_ = norm(x_, y_)
o__ = norm2(x_, y_)
o_.shape, o__.shape
o_
o__
a = (x_**2).sum(axis=-1)[..., None]
b = (y_**2).sum(axis=0)[None, ...]
c = jnp.einsum("i,ij -> j", x_, y_)
a.shape, b.shape, (a + b).shape, c.shape
x_.shape, y_.shape
from jejeqx._src.nets.nerfs.mfn import GaborLayer
layer = GaborLayer(2, 3)
layer(x_init[0])
# initialize model
model_config = OmegaConf.structured(MFNModel())
model = hydra.utils.instantiate(model_config)
# eqx.tree_pprint(model)
seed = 123
debug = False
enable_progress_bar = False
log_dir = "./"
trainer = RegressorTrainer(
model,
optimizer,
seed=seed,
debug=debug,
enable_progress_bar=enable_progress_bar,
log_dir=log_dir,
)
train_more = True
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
try:
trainer.load_model("./checkpoints/checkpoint_model_mfngabor.ckpt")
except:
pass
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
%%time
#
if train_more:
metrics = trainer.train_model(dm, num_epochs=num_epochs)
if train_more:
trainer.save_model("./checkpoints/checkpoint_model_mfngabor.ckpt")
out, metrics = trainer.test_model(dm.test_dataloader())
metrics
all_metrics = pd.concat(
[
all_metrics,
pd.DataFrame(
data=[["mfngabor", metrics["loss"], metrics["psnr"]]],
columns=["model", "MSE", "SNR"],
),
]
)
out_mfn_gabor = dm.coordinates_2_image(out)
fig, ax = plt.subplots(ncols=2, nrows=3, figsize=(8, 8))
ax[0, 0].imshow(img)
ax[0, 0].set(title="Original")
ax[0, 1].imshow(out_mlp)
ax[0, 1].set(title="MLP")
ax[1, 0].imshow(out_rff)
ax[1, 0].set(title="Fourier Features")
ax[1, 1].imshow(out_siren)
ax[1, 1].set(title="Siren")
ax[2, 0].imshow(out_mfn_fourier)
ax[2, 0].set(title="MFN (Fourier)")
ax[2, 1].imshow(out_mfn_gabor)
ax[2, 1].set(title="MFN (Gabor)")
plt.tight_layout()
plt.show()
all_metrics