Change of variables from scratch
The one formula the whole curriculum is built on — 1D, 2D, d-D, both directions
00 — Change of variables from scratch¶
Every Gaussianization method in this curriculum — RBIG, coupling flows, FFJORD, spline flows — is a way of building an invertible map that turns messy data into a standard Gaussian. The single fact that makes any of this useful for density estimation is the change-of-variables formula Rezende & Mohamed (2015)Papamakarios et al. (2021): it tells us how a probability density transforms when we push it through . Get this one formula and its bookkeeping right and the rest of the course is engineering.
What you will see
- The 1D formula derived and checked against an analytic density.
- The -D generalisation , checked in 2D against a hand-computed determinant and in 5D against an autodiff Jacobian.
- Why we always work in log-space: .
- A
gauss_flowsbijector reporting the same our generic autodiff computation produces — the bridge from the math to the library.
import warnings
warnings.filterwarnings("ignore")
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from _style import GAUSS_KW, style_ax
jax.config.update("jax_enable_x64", True) # log-dets deserve float64
rng = np.random.default_rng(0)1. The 1D formula¶
Let be a continuous random variable with density , and let be a smooth, strictly monotone (hence invertible) map. Define . Conservation of probability mass over an infinitesimal interval says , and since ,
The factor is the 1D Jacobian: it is the local stretch/squeeze of the line under , and it is exactly what keeps the transformed density normalised.
Worked example. Take , i.e. with , and the map . Then is standard normal by construction, so we know the answer and can check the formula. Here , so the formula predicts .
# Sample X = exp(W), W ~ N(0,1).
W = rng.standard_normal(200_000)
X = np.exp(W)
# The map and its derivative (let JAX differentiate it so we never hand-code T').
T = jnp.log
dT = jax.vmap(jax.grad(T)) # T'(x) = 1/x
x_grid = jnp.linspace(0.05, 8.0, 400)
p_X = stats.lognorm.pdf(np.asarray(x_grid), s=1.0) # true p_X
# Change of variables: p_Z(z) at z = T(x) equals p_X(x) / |T'(x)|.
z_at = np.asarray(T(x_grid))
p_Z_pred = p_X / np.abs(np.asarray(dT(x_grid)))
fig, axes = plt.subplots(1, 2, figsize=(11, 4))
axes[0].hist(X, bins=200, density=True, range=(0, 8), color="tab:blue", alpha=0.5)
axes[0].plot(x_grid, p_X, "k-", lw=1.5, label=r"$p_X$ (lognormal)")
axes[0].set(title=r"data space: $X = e^W$", xlabel="x", ylabel="density")
axes[0].legend(); style_ax(axes[0])
zz = np.linspace(-4, 4, 400)
axes[1].hist(np.asarray(T(X)), bins=200, density=True, range=(-4, 4),
color="tab:orange", alpha=0.5, label="histogram of $Z=T(X)$")
axes[1].plot(z_at, p_Z_pred, "r-", lw=1.8, label=r"change-of-variables prediction")
axes[1].plot(zz, stats.norm.pdf(zz), **GAUSS_KW, label=r"$\mathcal{N}(0,1)$")
axes[1].set(title=r"latent space: $Z = \log X$", xlabel="z")
axes[1].legend(); style_ax(axes[1])
fig.tight_layout()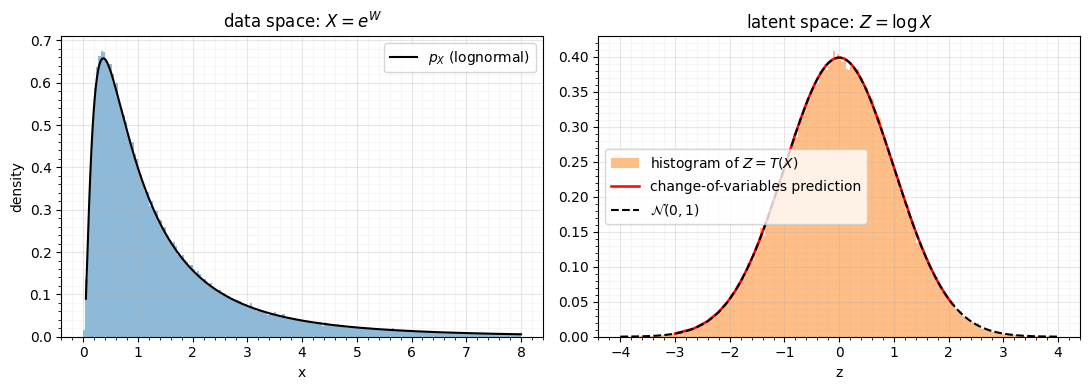
The red change-of-variables prediction lands exactly on both the empirical histogram of and the analytic curve. The factor is doing real work: drop it and the prediction would integrate to something other than 1.
2. The -dimensional formula¶
In dimensions the scalar derivative becomes the Jacobian matrix with , and its absolute determinant replaces :
is the local volume change: the factor by which inflates or shrinks a tiny box of probability mass around .
Linear case. For an affine map the Jacobian is constant, , so everywhere. We can read the answer off directly and check it.
A = jnp.array([[1.3, 0.7], [-0.4, 0.9]])
b = jnp.array([0.5, -1.0])
T_lin = lambda x: A @ x + b
x0 = jnp.array([0.3, -1.2])
J = jax.jacfwd(T_lin)(x0) # autodiff Jacobian at x0
print("autodiff Jacobian J_T(x0):\n", np.asarray(J))
print(f"|det J| (autodiff) = {abs(jnp.linalg.det(J)):.6f}")
print(f"|det A| (by hand) = {abs(jnp.linalg.det(A)):.6f}")
print(f"log|det J| (autodiff) = {jnp.linalg.slogdet(J)[1]:.6f}")autodiff Jacobian J_T(x0):
[[ 1.3 0.7]
[-0.4 0.9]]
|det J| (autodiff) = 1.450000
|det A| (by hand) = 1.450000
log|det J| (autodiff) = 0.371564
Seeing as area change. The determinant is not just a number to plug in — it is the factor by which scales area locally. We can watch this directly: lay a unit grid over the plane, push every cell through , and colour each warped cell by its Jacobian determinant. For the linear map every cell scales by the same (constant colour). For a nonlinear map the determinant varies with position — which is exactly why in general is a function of , evaluated afresh at every point.
from matplotlib.collections import PolyCollection
# A nonlinear map whose Jacobian determinant varies across the plane.
def T_wave(x):
return x + 0.5 * jnp.array([jnp.sin(1.5 * x[1]), jnp.sin(1.5 * x[0])])
def warp_grid(ax, fn, title, lo=-2.5, hi=2.5, n=14):
"""Push a unit grid through fn; colour each cell by its |det J| at the centre."""
edges = np.linspace(lo, hi, n + 1)
fn_v = jax.vmap(fn)
def absdet(p): # |det J_fn(p)| via autodiff Jacobian
return jnp.exp(jnp.linalg.slogdet(jax.jacfwd(fn)(p))[1])
polys, vals = [], []
for i in range(n):
for j in range(n):
corners = jnp.array([
[edges[i], edges[j]], [edges[i + 1], edges[j]],
[edges[i + 1], edges[j + 1]], [edges[i], edges[j + 1]],
])
polys.append(np.asarray(fn_v(corners)))
center = jnp.array([(edges[i] + edges[i + 1]) / 2,
(edges[j] + edges[j + 1]) / 2])
vals.append(float(absdet(center)))
pc = PolyCollection(polys, array=np.array(vals), cmap="viridis",
edgecolors="k", linewidths=0.25, alpha=0.95)
ax.add_collection(pc)
ax.autoscale_view()
ax.set_aspect("equal")
ax.set(title=title, xlabel="$z_1$", ylabel="$z_2$")
style_ax(ax)
return pc
fig, axes = plt.subplots(1, 2, figsize=(11, 4.6), constrained_layout=True)
warp_grid(axes[0], T_lin, r"linear $T(x)=Ax+b$: $|\det J|\equiv 1.45$")
pc = warp_grid(axes[1], T_wave, r"nonlinear $T$: $|\det J|$ varies with $x$")
fig.colorbar(pc, ax=axes, shrink=0.85, label=r"local area scaling $|\det J_T(x)|$")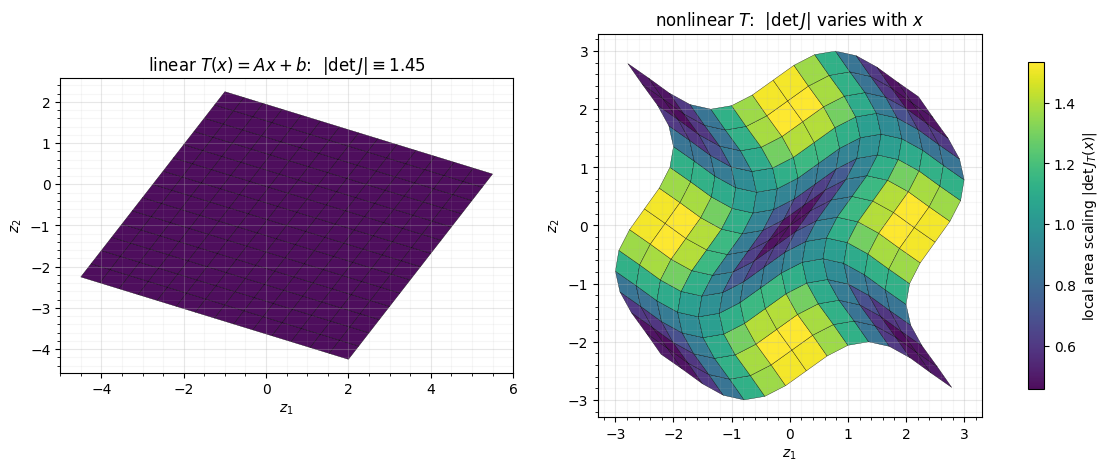
Left: a unit grid becomes a lattice of identical parallelograms — the linear map stretches area by the constant everywhere (uniform colour). Right: the same grid warps unevenly; cells in expanding regions are larger and brighter, compressed regions smaller and darker. The change-of-variables formula handles both cases identically because it reads off locally, at each .
3. Always work in log-space¶
Densities span many orders of magnitude and of a matrix is a product of numbers — both overflow/underflow fast. So in practice we never form directly; we accumulate its logarithm:
This is the equation a normalizing flow evaluates. jax.numpy.linalg.slogdet
returns stably (with a separate sign), which is exactly what we
want. Let’s verify the full log-density identity on a nonlinear map in 5D,
using an autodiff Jacobian so the check is completely generic.
d = 5
# A smooth invertible nonlinearity: elementwise tanh-shift composed with a
# fixed well-conditioned linear mixer. (Invertible because tanh is monotone and
# M is full rank — we only need it to be a local diffeomorphism for the check.)
M = jnp.asarray(rng.standard_normal((d, d)) * 0.3 + jnp.eye(d))
def T_nl(x):
return M @ jnp.tanh(0.7 * x) + 0.5 * x
def logdet_autodiff(x):
J = jax.jacfwd(T_nl)(x)
return jnp.linalg.slogdet(J)[1]
# Base density p_Z = N(0, I); pull a point through and score it two ways.
x = jnp.asarray(rng.standard_normal(d))
z = T_nl(x)
log_pz = jax.scipy.stats.multivariate_normal.logpdf(z, jnp.zeros(d), jnp.eye(d))
log_px = log_pz + logdet_autodiff(x)
print(f"log p_Z(T(x)) = {log_pz:.6f}")
print(f"log|det J_T(x)| = {logdet_autodiff(x):.6f}")
print(f"=> log p_X(x) = {log_px:.6f}")
# Monte-Carlo sanity check: the pushforward of x ~ p_X through T must be N(0,I).
# Equivalently the average log p_X over true X-samples should match the
# entropy-style identity E[log p_X(X)] = E[log p_Z(Z)] (T is a bijection).
xs = jnp.asarray(rng.standard_normal((4000, d))) # stand-in samples
batched = jax.vmap(lambda u: jax.scipy.stats.multivariate_normal.logpdf(
T_nl(u), jnp.zeros(d), jnp.eye(d)) + logdet_autodiff(u))(xs)
print(f"\nbatched log p_X over 4000 points: finite={bool(jnp.all(jnp.isfinite(batched)))}")log p_Z(T(x)) = -7.987257
log|det J_T(x)| = -0.126274
=> log p_X(x) = -8.113531
batched log p_X over 4000 points: finite=True
4. The bridge: a gauss_flows bijector reports this exact number¶
Every bijector in gauss_flows
exposes transform_and_log_det(x) -> (z, log|det J|). That second return
value is the we have been computing — the library does
the bookkeeping analytically and cheaply (no determinant), but it
must agree with a brute-force autodiff Jacobian. Let’s confirm that on a
MixtureGaussianCDF marginal bijector, the workhorse of Gaussianization.
import gauss_flows as gf
bij = gf.MixtureGaussianCDF(n_components=8, shape=(d,))
xv = jnp.asarray(rng.standard_normal(d))
z_lib, logdet_lib = bij.transform_and_log_det(xv)
# Brute-force: differentiate the bijector's own transform and take slogdet.
J_lib = jax.jacfwd(bij.transform)(xv)
logdet_bruteforce = jnp.linalg.slogdet(J_lib)[1]
print(f"gauss_flows analytic log|det J| = {logdet_lib:.8f}")
print(f"autodiff-Jacobian log|det J| = {logdet_bruteforce:.8f}")
print(f"absolute difference = {abs(logdet_lib - logdet_bruteforce):.2e}")
assert jnp.allclose(logdet_lib, logdet_bruteforce, atol=1e-6)
print("\n[ok] the library's log-det is the change-of-variables Jacobian.")gauss_flows analytic log|det J| = 1.79662669
autodiff-Jacobian log|det J| = 1.79662669
absolute difference = 2.89e-15
[ok] the library's log-det is the change-of-variables Jacobian.
The two agree to floating-point precision. That is the whole point of this notebook: the abstract formula from §1–§3 is literally what the package returns, so once you trust the formula you can trust the library — and stop computing determinants by hand, because the analytic log-det is both exact and far cheaper.
Recap¶
| concept | formula | in code |
|---|---|---|
| 1D change of variables | p_X / abs(jax.grad(T)(x)) | |
| -D change of variables | slogdet(jax.jacfwd(T)(x)) | |
| log-density (what flows evaluate) | log_pz + log_det | |
| the library’s job | analytic, cheap | bij.transform_and_log_det(x) |
Next up. A single bijector is rarely enough. In 01 — Composition & the additive log-determinant we stack maps and show the log-dets simply add — the rule that lets us build deep flows.
- Rezende, D. J., & Mohamed, S. (2015). Variational Inference with Normalizing Flows. International Conference on Machine Learning (ICML).
- Papamakarios, G., Nalisnick, E., Rezende, D. J., Mohamed, S., & Lakshminarayanan, B. (2021). Normalizing Flows for Probabilistic Modeling and Inference. Journal of Machine Learning Research, 22(57), 1–64.