Software¶
- Author: J. Emmanuel Johnson
- Email: jemanjohnson34@gmail.com
- Last Updated: 18-Jan-2020
What is Deep Learning?¶
Before we get into the software, I just wanted to quickly define deep learning. A recent debate on twitter got me thinking about an appropriate definition and it helped me think about how this definition relates to the software. It gave me perspective.
Definition 1 by Yann LeCun - tweet (paraphrased)
Deep Learning is methodology: building a model by assembling parameterized modules into (possibly dynamic) graphs and optimizing it with gradient-based methods.
Definition II by Danilo Rezende - tweet (paraphrased)
Deep Learning is a collection of tools to build complex modular differentiable functions.
These definitions are more or less the same: deep learning is a tool to facilitate gradient-based optimization scheme for models. The data we use, the exact way we construct it, and how we train it aren't really in the definition. Most people might think a DL tool is the ensemble of different neural networks like these. But from henceforth, I refer to DL in the terms of facilitating the development of those neural networks, not the network library itself.
So in terms of DL software, we need only a few components:
- Tensor structures
- Automatic differentiation (AutoGrad)
- Model Framework (Layers, etc)
- Optimizers
- Loss Functions
Anything built on top of that can be special cases where we need special structures to create models for special cases. The simple example is a Multi-Layer Perceptron (MLP) model where we need some weight parameter, a bias parameter and an activation function. A library that allows you to train this model using an optimizer and a loss function, I would consider this autograd software (e.g. JAX). A library that has this functionality built-in (a.k.a. a layer), I would consider this deep learning software (e.g. TensorFlow, PyTorch). While the only difference is the level of encapsulation, the latter makes it much easier to build 'complex modular' neural networks whereas the former, not so much. You could still do it with the autograd library but you would have to design your entire model structure from scratch as well. So, there are still a LOT of things we can do with parameters and autograd alone but I wouldn't classify it as DL software. This isn't super important in the grand scheme of things but I think it's important to think about when creating a programming language and/or package and thinking about the target user.
Anatomy of good DL software¶
Francios Chollet (the creator of keras) has been very vocal about the benefits of how TensorFlow caters to a broad audience ranging from applied users and algorithm developers. Both sides of the audience have different needs so building software for both audiences can very, very challenging. Below I have included a really interesting figure which highlights the axis of operations.

Photo Credit: Francois Chollet Tweet
As shown, there are two axis which define one way to split the DL software styles: the x-axis covers the model construction process and the y-axis covers the training process. I am sure that this is just one way to break apart DL software but I find it a good abstract way to look at it because I find that we can classify most use cases somewhere along this graph. I'll briefly outline a few below:
- Case 1: All I care about is using a prebuilt model on some new data that my company has given me. I would probably fall somewhere on the upper right corner of the graph with the
Sequentialmodel and the built-intrainingscheme. - Case II: I need a slightly more complex training scheme because I want to learn two models that share hidden nodes but they're not the same size. I also want to do some sort of cycle training, i.e. train one model first and then train the other. Then I would probably fall somewhere near the middle, and slightly to the right with the
Functionalmodel and a customtrainingscheme. - Case III: I am a DL researcher and I need to control every single aspect of my model. I belong to the left and on the bottom with the full
subclassmodel and completely customtrainingscheme.
So there are many more special cases but by now you can imagine that most general cases can be found on the graph. I would like to stress that designing software to do all of these cases is not easy as these cases require careful design individually. It needs to be flexible.
Maybe I'm old school, but I like the modular way of design. So in essence, I think we should design libraries that focus on one aspect, one audience and do it well. I also like a standard practice and integration so that everything can fit together in the end and we can transfer information or products from one part to another. This is similar to how the Japanese revolutionized building cars by having one machine do one thing at a time and it all fit together via a standard assembly line. So in the end, I want people to be able to mix and match as they see fit. To try to please everyone with "one DL library that rules them all" seems a bit silly in my opinion because you're spreading out your resources. But then again, I've never built software from scratch and I'm not a mega coorperation like Google or Facebook, so what do I know? I'm just one user...in a sea of many.
With great power, comes great responsibility - Uncle Ben
On a side note, when you build popular libraries, you shape how a massive amount of people think about the problem. Just like expressiveness is only as good as your vocabulary and limited by your language, the software you create actively morphs how your users think about framing and solving their problems. Just something to think about.
Convergence of the Libraries¶
Originally, there was a lot of differences between the deep learning libraries, e.g. static v.s. dynamic, Sequential v.s. Subclass. But now they are all starting to converge or at least have similar ways of constructing models and training. Below is a quick example of 4 deep learning libraries. If you know your python DL libraries trivia, try and guess which library do you think it is. Click on the details below to find out the answer.
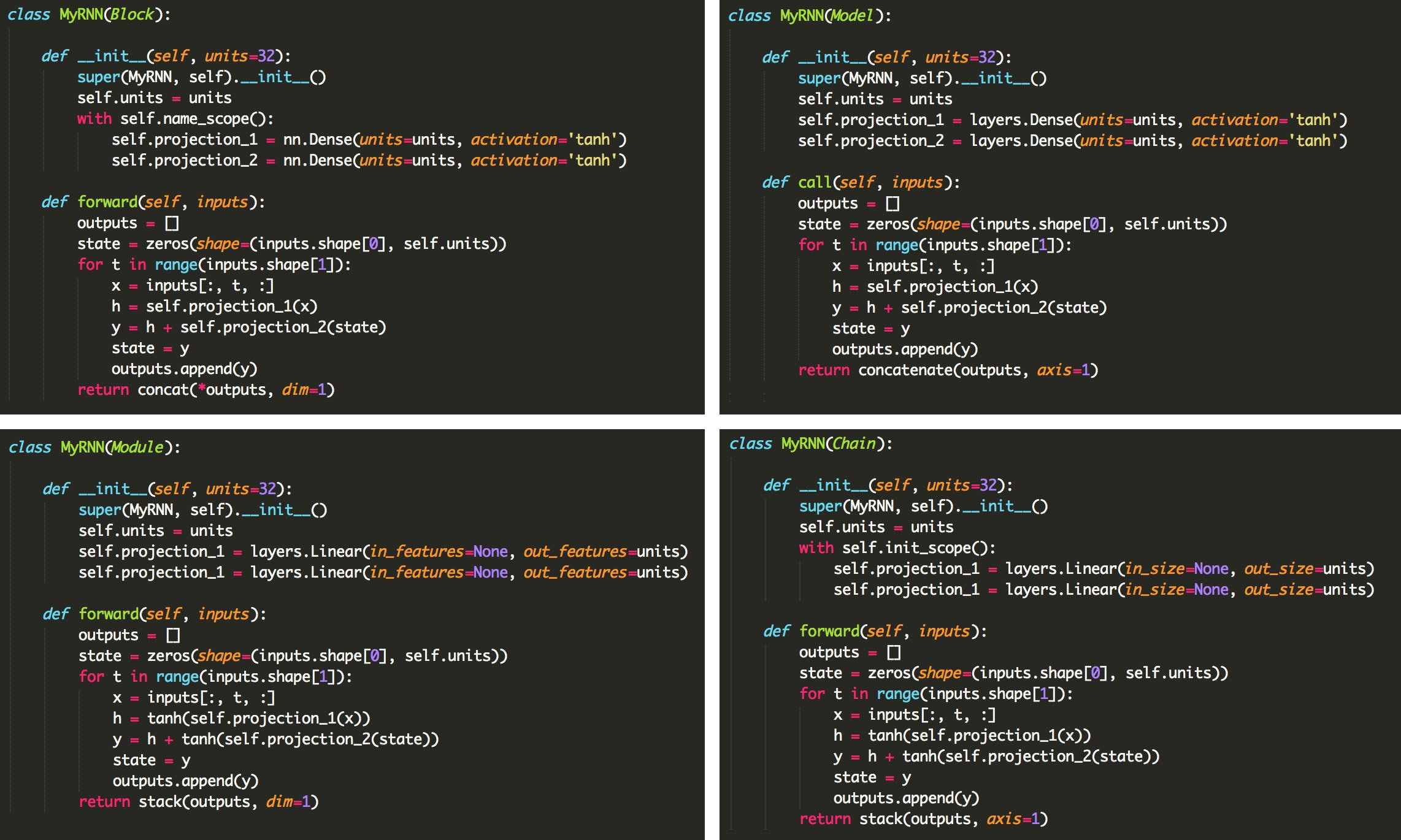
Photo Credit: Francois Chollet Tweet
Answer here:
| Gluon | TensorFlow |
| PyTorch | Chainer |
It does begs the question: if all of the libraries are basically the same, why are their multiple libraries? That's a great question and I do not know the answer to that. I think options are good as competition generally stimulates innovation. But at some point, there should be a limit no? But then again, the companies backing each of these languages are quite huge (Google, Microsoft, Uber, Facebook, etc). So I'm sure they have more than enough employees to justify the existence of their own library. But then again, imagine if they all put their efforts into making one great library. It could be an epic success! Or an epic disaster. I guess we will never know.
So what to choose?¶
There are many schools of thought. Some people suggest doing things from scratch while some favour software to allow users to jumping right in. Fortunately, whatever the case may be or where you're at in your ML journey, there is a library to suit your needs. And as seen above, most of them are converging so learning one python package will have be transferable to another. In the end, people are going to choose whatever based on personal factors such as "what is my style" or environmental factors such as "what is my research lab using now?".
I have a personal short list below just from observations, trends and reading but it is by no means concrete. Do whatever works for you!
Jump Right In - fastai
If you're interesting in applying your models to new and interesting datasets and are not necessarily interested in development then I suggest you start with fastai. This is a library that simplifies deep learning usage with all of the SOTA tricks built-in so I think it would save the average user a lot of time.
From Scratch - JAX
If you like to do things from scratch in a very numpy-like way but also want all of the benefits of autograd on CPU/GPU/TPUs, then this is for you.
Deep Learning Researcher - PyTorch
If you're doing research, then I suggest you use PyTorch. It is currently the most popular library for doing ML research. If you're looking at many of the SOTA algorithms, you'll find most of them being written in PyTorch these days. The API is similar to TensorFlow so you can easily transfer your skills to TF if needed.
Production/Industry - TensorFlow
TensorFlow holds the market in production. By far. So if you're looking to go into industry, it's highly likely that you'll be using TensorFlow. There are still a lot of researchers that use TF too. Fortunately, the API is similar to PyTorch if you use the subclass system so the skills are transferable.
!> Warning: The machine learning community changes rapidly so any trends you observe are extremely volatile. Just like the machine learning literature, what's popular today can change within 6 months. So don't ever lock yourself in and stay flexible to cope with the changes. But also don't jump on bandwagons either as you'll be jumping every weekend. Keep a good balance and maintain your mental health.
List of Software¶
There are many autograd libraries available right now. All of the big tech companies (Google, Facebook, Amazon, Microsoft, Uber, etc.) have a piece of the python software package pie. Fortunately for us, many of them have open-sourced so we get to enjoy high-quality, feature-filled, polished software for us to work with. I believe this, more than anything, has accelerated research in the computational world, in particular for people doing research related to machine learning.
Core Packages¶
TensorFlow (TF)¶
This is by far the most popular autograd library currently. Backed by Google (Alphabet, Inc), it is the go to python package for production and it is very popular for researchers as well. Recently (mid-2019) there was a huge update which made the python API much easier to use by having a tight keras integration and allowing for a more pythonic-style of coding.
TensorFlow Probability (TFP)
As the name suggests, this is a probabilistic library that is built on top of TensorFlow. It has many distributions, priors, and inference methods. In addition, it uses the same layers as the tf.keras library with some edward2 integration.
Edward2 (Ed2)
While there is some integration of edward2 into the TFP library, there are some stand alone functions in the original Ed2 library. Some more advanced layers such as Sparse Gaussian processes and Noise contrastive priors. It all works seemlessly with TF and TFP.
GPFlow (GPF)
This is a special library for SOTA GPs that's built on top of TF. It is the success to the original GP library, GPy but it has a much cleaner code base and a bit better documentation due to its use of autograd.
PyTorch¶
This is the most popular DL library for the machine learning community. Backed by Facebook, this is a rather new library that came out 2 years ago. It took a bit of time, but eventually people started using it more and more especially in a research setting. The reason is because it is very pythonic, it was designed by researchers and for researchers, and it keeps the design simple even sacrificing speed if needed. If you're starting out, most people will recommend you start with PyTorch.
This is a popular Bayesian DL library that is built on top of PyTorch. Backed by Uber, you'll find a lot of different inference scheme. This library is a bit of a learning curve because their API. But, their documentation and tutorial section is great so if you take your time you should pick it up. Unfortunately I don't find too many papers with Pyro code examples, but when the Bayesian community gets bigger, I'm sure this will change.
This is the most scalable GP library currently that's built on top of PyTorch. They mainly use Matrix-Vector-Multiplication strategies to scale exact GPs up to 1 million points using multiple GPUs. They recently just revamped their documentation as well with many examples. If you plan to put GPs in production, you should definitely check out this library.
This is a DL library that was created to facilate people using some of the SOTA NN methods to solve problems. It was created by Jeremy Howard and has gained popularity due to its simplicity. It has all of the SOTA parameters by default and there are many options to tune your models as you see fit. In addition, it has a huge community with a very active forum. I think it's a good first pass if you're looking to solve real problems and get your feet wet while not getting too hung up on the model building code. They also have 2 really good courses that teach you the mechanics of ML and DL while still giving you enough tools to make you a competitive.
This is the successor for the popular autograd package that is now backed by Google. It is basically numpy on steroids giving you access to an autograd function and it can be used on CPUs, GPUs and TPUs. The gradients are very intuitive as it is just using a grad function; recursively if you want high-order gradients. It's still fairly early in development but it's gaining popularity very fast and has shown to be very competitive. It's fast. Really fast. To really take advantage of this library, you will need to do a more functional-style of programming but there have been many benefits, e.g. using it for MCMC sampling schemes has become popular.
Other Packages¶
Although these are in the 'other' category, it doesn't mean that they are lower tier by any means. I just put them here because I'm not too familiar with them outside of the media.
Preferred Networks (Japanese Company)
Amazon
maintained by the PyMC3 developers.
Microsoft