The Multivariate Gaussian: density, sampling, conditioning
The multivariate normal (MVN) distribution is the workhorse of Gaussian processes, Kalman filtering, and most of variational inference. This notebook is the pedagogical entry point for the GP tutorial sequence: by the end you should have a working mental model of and a feel for the three operations every later notebook will lean on — evaluating the density, drawing samples, and conditioning on a sub-vector.
What you’ll learn
- The MVN density, its level sets, and why must be positive definite.
- Three equivalent ways to sample from an MVN, all driven by the same standard-normal noise.
- How marginalization and conditioning act on — the Schur complement.
- Why naive
inv(Sigma)is a bad idea, and whatgaussxgives you instead.
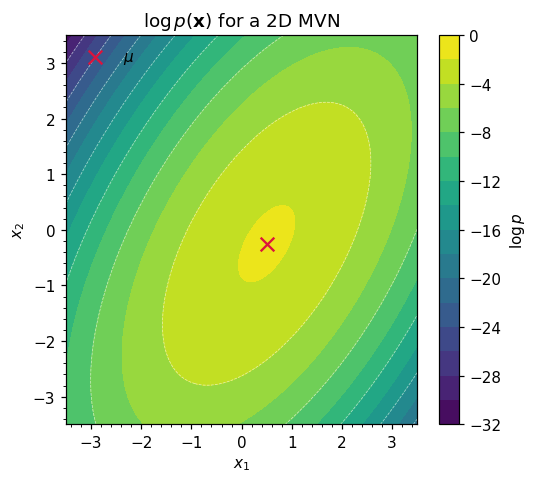
1. The density¶
A random vector is multivariate normal with mean and covariance when its density is
Three things are doing real work in equation ((1)):
- is a squared Mahalanobis distance — the Euclidean norm rescaled by the geometry of .
- is a normalization that makes the density integrate to 1; it grows when shrinks.
- must be symmetric positive-definite (SPD) so that the quadratic form is non-negative, the inverse exists, and the density is well defined.
The log density is the version we actually compute, because is much more stable than :
from __future__ import annotations
import warnings
warnings.filterwarnings("ignore", message=r".*IProgress.*")
import einx
import jax
import jax.numpy as jnp
import lineax as lx
import matplotlib.pyplot as plt
import numpy as np
from gaussx import (
MultivariateNormal,
add_jitter,
cholesky,
conditional,
gaussian_log_prob,
schur_complement,
solve,
sqrt,
)
jax.config.update("jax_enable_x64", True)
KEY = jax.random.PRNGKey(0)
plt.rcParams.update({
"figure.dpi": 110,
"axes.grid": True,
"axes.grid.which": "both",
"xtick.minor.visible": True,
"ytick.minor.visible": True,
"grid.alpha": 0.3,
})
mu = jnp.array([0.5, -0.25])
Sigma = jnp.array([[1.0, 0.7],
[0.7, 1.5]])
Sigma_op = lx.MatrixLinearOperator(Sigma, lx.positive_semidefinite_tag)
p = MultivariateNormal(mu, Sigma_op)
print("event_shape :", p.event_shape)
print("mean :", np.asarray(p.mean))
print("variance :", np.asarray(p.variance))
print("log p(mu) :", float(p.log_prob(mu)))
event_shape : (2,)
mean : [ 0.5 -0.25]
variance : [1. 1.5]
log p(mu) : -1.8428522318359293
xs = jnp.linspace(-3.5, 3.5, 200)
ys = jnp.linspace(-3.5, 3.5, 200)
XX, YY = jnp.meshgrid(xs, ys)
grid = jnp.stack([XX.ravel(), YY.ravel()], axis=-1)
logp = jax.vmap(p.log_prob)(grid).reshape(XX.shape)
fig, ax = plt.subplots(figsize=(5.0, 4.5))
cs = ax.contourf(np.asarray(XX), np.asarray(YY), np.asarray(logp), levels=18, cmap="viridis")
ax.contour(np.asarray(XX), np.asarray(YY), np.asarray(logp), levels=8, colors="white", linewidths=0.5, alpha=0.6)
ax.scatter(*np.asarray(mu), color="crimson", marker="x", s=80, label=r"$\mu$")
ax.set_xlabel(r"$x_1$"); ax.set_ylabel(r"$x_2$")
ax.set_title(r"$\log p(\mathbf{x})$ for a 2D MVN")
ax.legend(loc="upper left", frameon=False)
ax.grid(False, which="both") # contourf already conveys density — grid is noise here
plt.colorbar(cs, ax=ax, label=r"$\log p$")
plt.tight_layout(); plt.show()
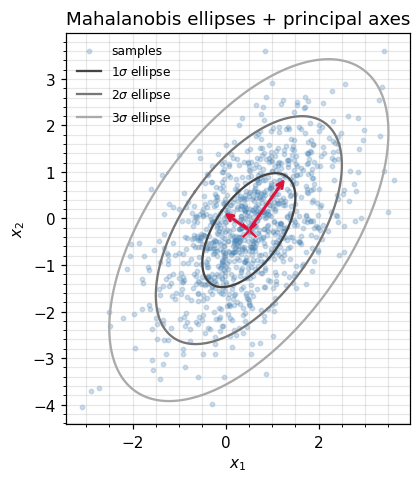
2. The geometry of the covariance¶
The level sets of equation ((1)) are ellipsoids defined by
and the eigendecomposition
reads off those ellipsoids directly: the columns of are the principal axes, and is the radius along axis . So is geometry — orientation plus scale — and SPD-ness is exactly the requirement that all principal radii be real and positive.
The figure below draws 1-, 2-, and 3-σ Mahalanobis ellipses on top of samples from and overlays the principal axes. The two eigenvalues differ by , which is why the cloud is visibly elongated.
eigvals, eigvecs = jnp.linalg.eigh(Sigma)
print("eigenvalues :", np.asarray(eigvals))
print("eigenvectors (columns):\n", np.asarray(eigvecs))
samples = p.sample(jax.random.PRNGKey(1), (1000,))
theta = jnp.linspace(0, 2 * jnp.pi, 200)
unit_circle = jnp.stack([jnp.cos(theta), jnp.sin(theta)], axis=0) # (axis=2, theta=200)
# Stretch the unit circle by the principal radii sqrt(lambda), then rotate by Q:
# ellipse = Q @ diag(sqrt(lambda)) @ unit_circle
# Done in two einx.dot steps to keep every index named.
sqrt_lambda = jnp.sqrt(eigvals)
stretched = einx.multiply("j, j t -> j t", sqrt_lambda, unit_circle)
ellipse_template = einx.dot("i j, j t -> i t", eigvecs, stretched)
fig, ax = plt.subplots(figsize=(5.0, 4.5))
ax.scatter(*np.asarray(samples).T, s=8, alpha=0.25, color="steelblue", label="samples")
for c, color in zip([1.0, 2.0, 3.0], ["#444", "#777", "#aaa"]):
ellipse = c * ellipse_template
ax.plot(np.asarray(ellipse[0]) + float(mu[0]),
np.asarray(ellipse[1]) + float(mu[1]),
color=color, lw=1.5, label=fr"${int(c)}\sigma$ ellipse")
for i in range(2):
axis = np.asarray(eigvecs[:, i]) * np.sqrt(float(eigvals[i]))
ax.annotate("", xy=np.asarray(mu) + axis, xytext=np.asarray(mu),
arrowprops=dict(arrowstyle="->", color="crimson", lw=2.0))
ax.scatter(*np.asarray(mu), color="crimson", marker="x", s=80)
ax.set_aspect("equal")
ax.set_xlabel(r"$x_1$"); ax.set_ylabel(r"$x_2$")
ax.set_title("Mahalanobis ellipses + principal axes")
ax.legend(loc="upper left", frameon=False, fontsize=8)
plt.tight_layout(); plt.show()
eigenvalues : [0.50669656 1.99330344]
eigenvectors (columns):
[[-0.81741556 0.57604844]
[ 0.57604844 0.81741556]]
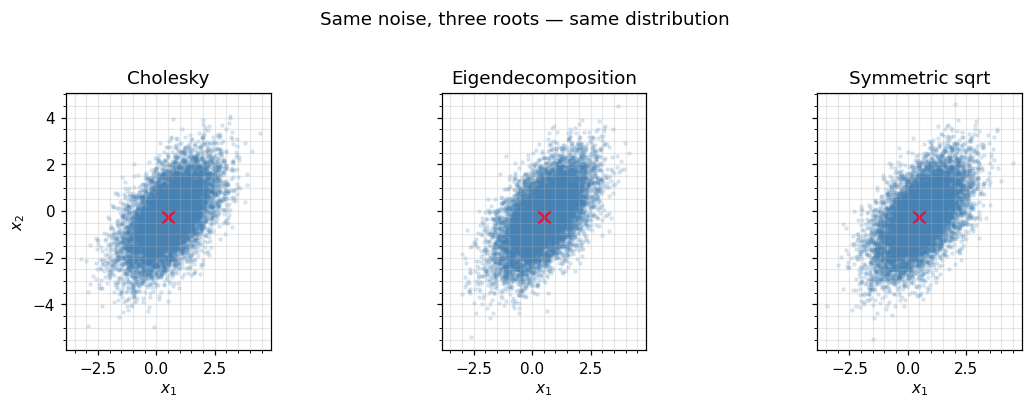
3. Three ways to sample¶
Sampling an MVN reduces to whitening in reverse: take standard normal noise and multiply by any matrix square root of . Concretely, if then
Three common choices for :
- Cholesky factor — , the unique lower-triangular with positive diagonal such that . Cheapest, most stable, the default in
gaussx. - Eigendecomposition — from equation ((4)). Useful when you need the principal axes anyway, or when has known structure.
- Symmetric square root — , the unique SPD matrix with . Has the nice property of being symmetric, occasionally needed for re-symmetrising updates (e.g. ensemble Kalman square-root filters).
All three give the same distribution. Below we drive each route with the same noise and check that the empirical covariance matches .
d = 2
N = 10_000
eps = jax.random.normal(jax.random.PRNGKey(2), (N, d))
def transform(eps, R):
"""x_n = mu + R @ eps_n, batched over n. einx names every index."""
return mu + einx.dot("n j, i j -> n i", eps, R)
# 1. Cholesky: L Lᵀ = Sigma
L = cholesky(Sigma_op).as_matrix()
samples_chol = transform(eps, L)
# 2. Eigendecomposition: R = Q diag(sqrt(lambda)) — scale columns of Q by sqrt(lambda).
R_eig = einx.multiply("i j, j -> i j", eigvecs, jnp.sqrt(eigvals))
samples_eig = transform(eps, R_eig)
# 3. Symmetric square root via gaussx.sqrt: R R = Sigma, R = Rᵀ
R_sym = sqrt(Sigma_op).as_matrix()
samples_sym = transform(eps, R_sym)
def empirical_cov(s):
s_centred = s - s.mean(axis=0, keepdims=True)
# (1 / (N-1)) * sum_n s_n s_nᵀ
return einx.dot("n i, n j -> i j", s_centred, s_centred) / (s.shape[0] - 1)
for label, s in [("Cholesky", samples_chol),
("Eigendecomp", samples_eig),
("Symmetric sqrt", samples_sym)]:
err = float(jnp.linalg.norm(empirical_cov(s) - Sigma))
print(f" {label:16s} -> ||emp_cov - Sigma||_F = {err:.4f}")
# Verify the symmetric sqrt really is symmetric (and squares to Sigma)
R_sym_squared = einx.dot("i j, j k -> i k", R_sym, R_sym)
print("\nsymmetric? ", bool(jnp.allclose(R_sym, R_sym.T)))
print("R_sym @ R_sym ≈ Sigma:", bool(jnp.allclose(R_sym_squared, Sigma, atol=1e-8)))
Cholesky -> ||emp_cov - Sigma||_F = 0.0179
Eigendecomp -> ||emp_cov - Sigma||_F = 0.0409
Symmetric sqrt -> ||emp_cov - Sigma||_F = 0.0235
symmetric? True
R_sym @ R_sym ≈ Sigma: True
fig, axes = plt.subplots(1, 3, figsize=(11, 3.6), sharex=True, sharey=True)
for ax, s, title in zip(axes,
[samples_chol, samples_eig, samples_sym],
["Cholesky", "Eigendecomposition", "Symmetric sqrt"]):
ax.scatter(*np.asarray(s).T, s=4, alpha=0.15, color="steelblue")
ax.scatter(*np.asarray(mu), marker="x", color="crimson", s=70)
ax.set_aspect("equal"); ax.set_title(title)
ax.set_xlabel(r"$x_1$")
axes[0].set_ylabel(r"$x_2$")
fig.suptitle("Same noise, three roots — same distribution", y=1.02)
plt.tight_layout(); plt.show()
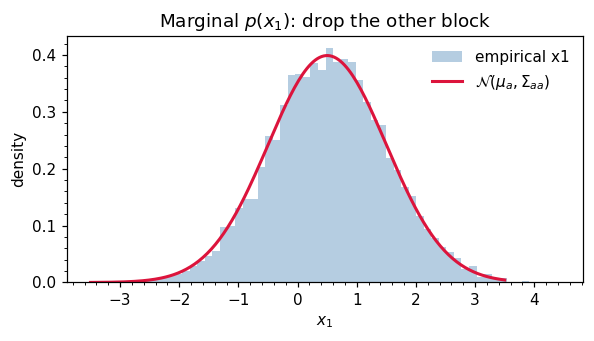
4. Marginalization¶
Partition with and , and write the joint as
The marginal of is obtained simply by dropping the rows and columns:
This is striking: marginalization is “look up the right block”. Compare the cost of integrating out from the joint density by hand — which involves completing the square — to the act of indexing into a matrix. The integral is automatic for Gaussians.
mu_a = mu[:1]
Sigma_aa = Sigma[:1, :1]
print("marginal mean :", np.asarray(mu_a))
print("marginal variance:", float(Sigma_aa[0, 0]))
# Sanity: empirical marginal of x_1 from joint samples
fig, ax = plt.subplots(figsize=(5.5, 3.2))
ax.hist(np.asarray(samples_chol[:, 0]), bins=60, density=True,
color="steelblue", alpha=0.4, label="empirical x1")
xs1 = jnp.linspace(-3.5, 3.5, 200)
pdf = jnp.exp(-0.5 * ((xs1 - mu_a) / jnp.sqrt(Sigma_aa))**2) / jnp.sqrt(2 * jnp.pi * Sigma_aa)
ax.plot(np.asarray(xs1), np.asarray(pdf).ravel(), color="crimson", lw=2, label=r"$\mathcal{N}(\mu_a, \Sigma_{aa})$")
ax.set_xlabel(r"$x_1$"); ax.set_ylabel("density")
ax.set_title("Marginal $p(x_1)$: drop the other block")
ax.legend(frameon=False)
ax.grid(False, which="both") # filled histogram bars are the background — grid would compete
plt.tight_layout(); plt.show()
marginal mean : [0.5]
marginal variance: 1.0
5. Conditioning — the Schur complement¶
The conditional is also Gaussian, with mean and covariance
The matrix is called the Schur complement of in . Two useful intuitions:
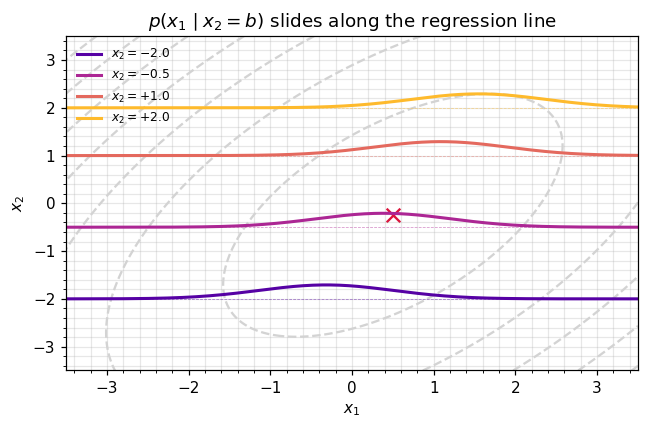
- Mean shift. Equation ((8)) is a linear regression: we subtract the prior on , regress the residual onto via the cross-covariance, and add it to the prior mean of . The regression coefficient is .
- Variance reduction. Equation ((9)) shows — observing never increases uncertainty in . The reduction is exactly the variance “explained” by .
gaussx provides conditional(loc, cov, obs_idx, obs_values) and schur_complement(K_XX, K_XZ, K_ZZ) — equation ((9)). We use the high-level conditional here.
def cond_density(b_value: float):
"""p(x_1 | x_2 = b_value) — returns (mean, std)."""
new_loc, new_cov_op = conditional(
loc=mu,
cov=Sigma_op,
obs_idx=jnp.array([1]),
obs_values=jnp.array([b_value]),
)
new_cov = new_cov_op.as_matrix()
return float(new_loc[0]), float(jnp.sqrt(new_cov[0, 0]))
for b in [-2.0, -0.5, 0.0, 1.5]:
m, s = cond_density(b)
print(f" x_2 = {b:+.2f} -> x_1 | x_2 ~ N({m:+.3f}, {s**2:.3f})")
x_2 = -2.00 -> x_1 | x_2 ~ N(-0.317, 0.673)
x_2 = -0.50 -> x_1 | x_2 ~ N(+0.383, 0.673)
x_2 = +0.00 -> x_1 | x_2 ~ N(+0.617, 0.673)
x_2 = +1.50 -> x_1 | x_2 ~ N(+1.317, 0.673)
fig, ax = plt.subplots(figsize=(6.0, 4.0))
ax.contour(np.asarray(XX), np.asarray(YY), np.asarray(logp), levels=8, colors="lightgray")
ax.scatter(*np.asarray(mu), marker="x", color="crimson", s=80)
xs1 = jnp.linspace(-3.5, 3.5, 300)
b_values = [-2.0, -0.5, 1.0, 2.0]
colors = plt.cm.plasma(np.linspace(0.15, 0.85, len(b_values)))
for b, col in zip(b_values, colors):
m, s = cond_density(b)
pdf = jnp.exp(-0.5 * ((xs1 - m) / s) ** 2) / (s * jnp.sqrt(2 * jnp.pi))
# Plot conditional density along x_2 = b, scaled for visibility
ax.plot(np.asarray(xs1), b + 0.6 * np.asarray(pdf), color=col, lw=2,
label=fr"$x_2 = {b:+.1f}$")
ax.axhline(b, color=col, lw=0.5, ls="--", alpha=0.5)
ax.set_xlabel(r"$x_1$"); ax.set_ylabel(r"$x_2$")
ax.set_title(r"$p(x_1 \mid x_2 = b)$ slides along the regression line")
ax.legend(frameon=False, fontsize=8, loc="upper left")
plt.tight_layout(); plt.show()
6. Numerical mechanics: don’t inv(Sigma)¶
Equations ((1)), ((2)), ((8)), and ((9)) all contain . You never form that inverse. Two reasons:
- Cost. Forming explicitly is and then every subsequent multiply is . Cholesky-factoring once and doing two triangular solves is also — but with a smaller constant — and reuses the factor for the log-determinant.
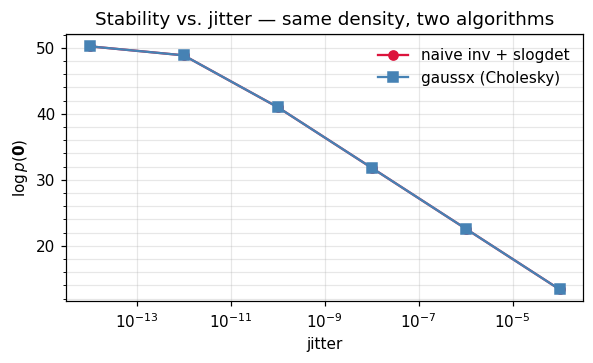
- Stability. Triangular solves preserve more digits than explicit inversion. The condition number of is , which is much friendlier than itself.
The recipe gaussx uses internally is
and when is borderline-PD (e.g. a kernel matrix on nearly-coincident inputs), we add a tiny multiple of the identity — jitter — until the Cholesky succeeds.
# Build a deliberately ill-conditioned covariance: two nearly-collinear cols.
d_test = 5
A = jnp.array([[1.0, 0.999, 0.5, 0.2, 0.1]]) # row vector, shape (1, d_test)
# Sigma = Aᵀ A + 1e-12 I — written with named indices via einx.
Sigma_bad = einx.dot("k i, k j -> i j", A, A) + 1e-12 * jnp.eye(d_test)
kappa = float(jnp.linalg.cond(Sigma_bad))
print(f"cond(Sigma) ~ {kappa:.2e}")
x_test = jnp.zeros(d_test)
mu_test = jnp.zeros(d_test)
delta = x_test - mu_test
# Naive: explicit inverse + log|det|, quadratic form via einx.
Sinv = jnp.linalg.inv(Sigma_bad)
sign, logabsdet = jnp.linalg.slogdet(Sigma_bad)
quad_naive = einx.dot("i, i j, j ->", delta, Sinv, delta)
logp_naive = -0.5 * d_test * jnp.log(2 * jnp.pi) - 0.5 * logabsdet - 0.5 * quad_naive
# Robust: jitter + Cholesky via gaussx
Sigma_op_bad = lx.MatrixLinearOperator(Sigma_bad, lx.positive_semidefinite_tag)
Sigma_op_jit = add_jitter(Sigma_op_bad, jitter=1e-8)
logp_gaussx = float(gaussian_log_prob(mu_test, Sigma_op_jit, x_test))
print(f"naive log p : {float(logp_naive):+.6f} (sign|det| = {int(sign):+d})")
print(f"gaussx log p : {logp_gaussx:+.6f}")
cond(Sigma) ~ 2.30e+12
naive log p : +50.251326 (sign|det| = +1)
gaussx log p : +31.830449
# Sweep jitter and watch the naive route fall apart while gaussx stays sane.
jitters = jnp.array([1e-14, 1e-12, 1e-10, 1e-8, 1e-6, 1e-4])
naive, robust = [], []
for j in jitters:
S = Sigma_bad + j * jnp.eye(d_test)
try:
Sinv = jnp.linalg.inv(S)
_, lad = jnp.linalg.slogdet(S)
lp = -0.5 * d_test * jnp.log(2 * jnp.pi) - 0.5 * lad
naive.append(float(lp))
except Exception:
naive.append(np.nan)
op = lx.MatrixLinearOperator(S, lx.positive_semidefinite_tag)
try:
robust.append(float(gaussian_log_prob(mu_test, op, x_test)))
except Exception:
robust.append(np.nan)
fig, ax = plt.subplots(figsize=(5.5, 3.4))
ax.plot(np.asarray(jitters), naive, "o-", label="naive inv + slogdet", color="crimson")
ax.plot(np.asarray(jitters), robust, "s-", label="gaussx (Cholesky)", color="steelblue")
ax.set_xscale("log")
ax.set_xlabel("jitter"); ax.set_ylabel(r"$\log p(\mathbf{0})$")
ax.set_title("Stability vs. jitter — same density, two algorithms")
ax.legend(frameon=False); plt.tight_layout(); plt.show()
7. Recap & where to go next¶
You now have the operational core of the multivariate Gaussian:
| Operation | Equation | gaussx entry point |
|---|---|---|
| Density | ((1)) | MultivariateNormal.log_prob / gaussian_log_prob |
| Sampling | ((5)) | MultivariateNormal.sample |
| Marginal | ((7)) | block selection |
| Conditional | ((8)), ((9)) | conditional, schur_complement |
| Stable log-prob | ((10)) | cholesky + solve |
Next up.
- 0.2 —
MultivariateNormal&MultivariateNormalPrecisionAPI tour: systematic walkthrough of the distribution objects, including the precision parametrization that’s preferred for sparse / Markov-structured covariances. - 0.3 — Quadratic forms, entropy, and KL between Gaussians: the closed-form quantities that make Gaussian variational inference and information-geometric methods tractable.
For the linear-algebra toolbox under the hood, jump to 0.9 — Cholesky, log-det, and trace primitives and Part 1.D — Solvers.